Propeller日記 (3)
長嶋 洋一
Propeller日記(1)
2008年3月20日(木)
Propeller Demo Boardには、既に実験したビデオ出力だけでなく、 ステレオのヘッドホンアンプに出力するオーディオ出力回路と、 オンボードのコンデンサマイクでサウンドを入力できるオーディオ入力回路が搭載されている。 これを実験しない手はないので、次には、オーディオ関係を調べてみることにした。 トラ技の紹介記事 の中でも、サンプルとしてスピーチ音声を再生したとか、 マイクの音がそこそこ良かった、と書いてあった。Propellerのサイトのダウンロードページの中のThe Propeller Object Exchangeのライブラリからそれらしきものを探すと、Speech & Soundのカテゴリの中に、
と並んでいた。後の2つは、前2つのサンプルからも利用されるライブラリということで、 とりあえず「歌う」デモは前の2つのようだ。
- Singing (16th Century, 4-part Harmony)
- Singing (Seven)
- Vocal Tract
- Stereo Spatializer
さっそくまず、「Singing (16th Century, 4-part Harmony)」をダウンロード、 解凍して、Propeller ToolでSingingDemo.spinを指定して、 とりあえずF10でコンパイル・実行してみると、Propeller Demo Boardのヘッドホン端子から出て来たのが、 これ(644KB MP3) である。ノイズはあるものの、なかなかやる。(^_^)
次に、「Singing (Seven)」をダウンロード、 解凍して、Propeller ToolでSingingDemoSeven.spinを指定して、 とりあえずF10でコンパイル・実行してみると、Propeller Demo Boardのヘッドホン端子から出て来たのが、 これ(1.7MB MP3) である。こちらもなかなかやる。
Propellerのシステムでは、各Cogsの内部RAM容量が非常に小さいだけでなく、 チップ上に共通に持っているRAMもかなり小さい。 また、フォントやサイン/logデータテーブル以外に、ユーザが格納できるROMは無い。 そして、外部ストレージもEEPROMはオプションであり、要するに、この長大なサウンドデータは、 「再生」でなくて「リアルタイム合成」でなければ実現できない。そこが凄いのだ。
3番目の「Vocal Tract」を調べてみると、歌うプログラムから使われるライブラリとしてだけでなく、 この「話す」機能の単独のデモもあることが判った。 Propeller ToolでVocalTractDemo_mama.spinを指定して、 とりあえずF10でコンパイル・実行してみると、Propeller Demo Boardのヘッドホン端子から出て来たのが、 これ(736KB MP3) である。 これがエンドレスに続く。 これがどうも、見た感じが一番シンプルだったので、以下のように関係のspinソースを全て作業エリアにコピーして、 調べてみることにした。
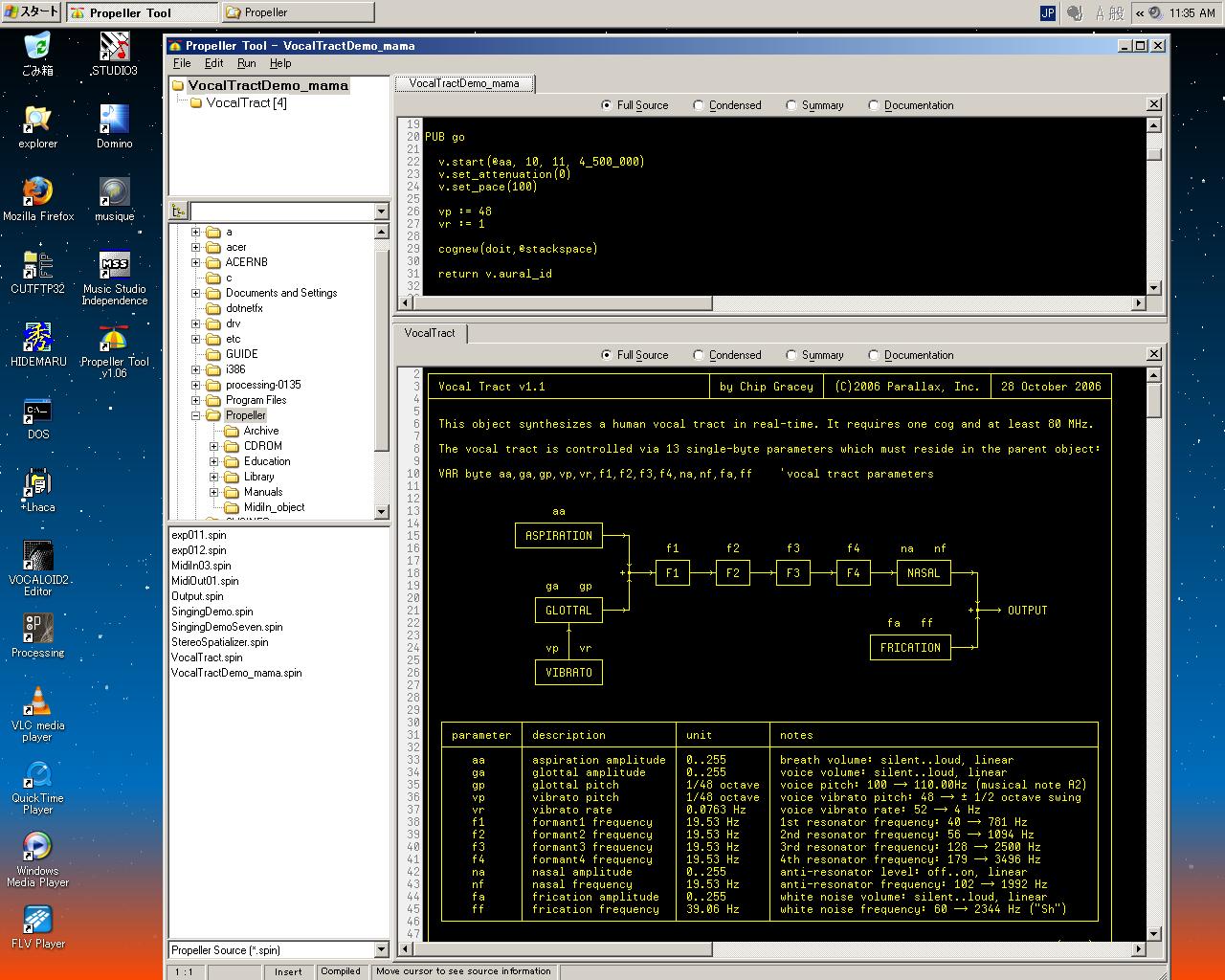
上のスクリーンショットのPropeller Tool画面のうち、上段が呼び出し側であり、 呼ばれる下段のVocalTract.spinの冒頭には、きちんと音素合成・フォルマント合成している原理が描かれている。
Propeller Demo Boardの回路図のうち、オーディオ入出力の部分は以下である。 この回路で実際にデモが動いているので、オーディオ出力ポートはP10とP11である。 検波・平滑回路というわけでもなく、これでどうやってアナログのオーディオ信号となるのか、 おそらくGAINERと同じようにPWMだろうと予想しつつ、このあたりから調べることになりそうだ。

基本的にはこれまでのオブジェクト資産を統合してどこまで行けるかを実験するので、 MIDI入力とMIDI出力のライブラリも利用しつつ、さらにビデオ出力もモニタとして使用する。 まず最初にexp012.spinをコピーしてリネームしたexp013.spinを作り、
というような機能を目指して、exp013.spinのMainを以下のように改造した。 あまりPropellerでの音声合成に入り込むつもりはないが、 なかなかしっかりと出来て、面白い「音声サウンド」の実験ツールとなった。
- MIDI入力をソフトスルーMIDI出力する
- このMIDI情報をビデオ画面の16進表示
- (鳴りっぱなしの)VocalTractを、特定のMIDI情報でMax/MSPからON/OFFする
- その他の音声合成パラメータも適宜、Max/MSPから制御
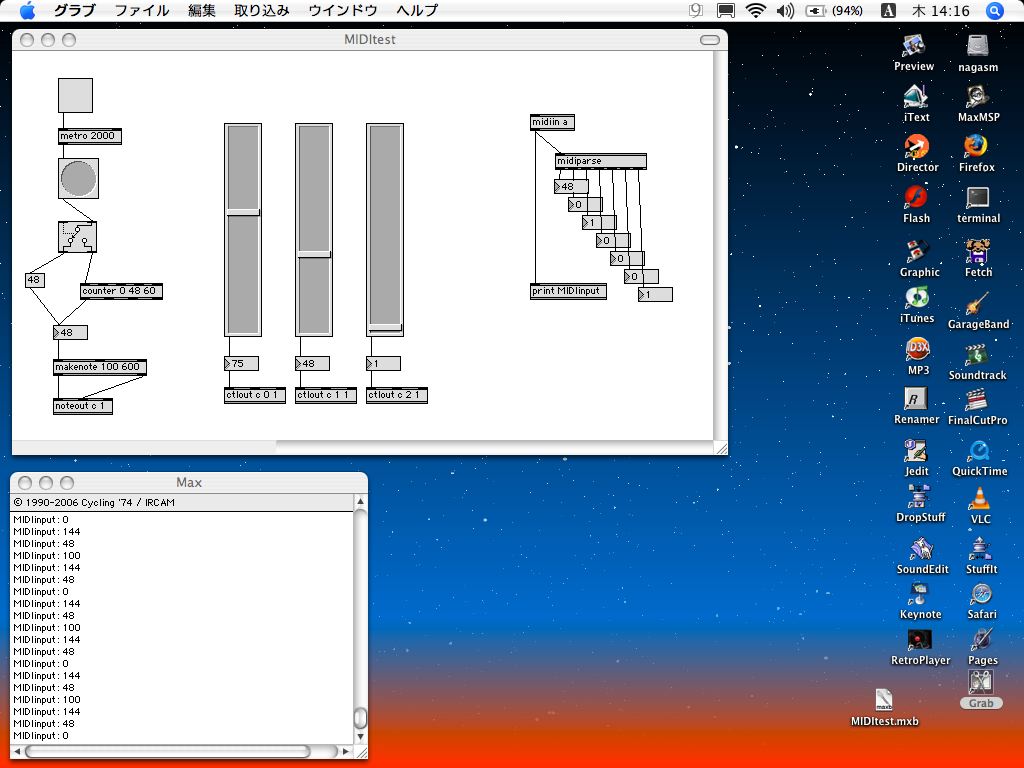
{{ exp013.spin }} CON _clkmode = xtal1 + pll16x _xinfreq = 5_000_000 jj = 19 OBJ Num : "Numbers" TV : "TV_Terminal" midiIn : "MidiIn03" midiOut : "MidiOut01" v[4] : "VocalTract" VAR long stackspace[40] byte aa,ga,gp,vp,vr,f1,f2,f3,f4,na,nf,fa,ff PUB Main | dummy Num.Init TV.Start(12) TV.Str(string("MIDI_input_Cog =")) dummy := midiIn.start(7) TV.Str(Num.ToStr(dummy, Num#DEC)) TV.Str(string(", MIDI_output_Cog =")) dummy := midiOut.start(6) TV.Str(Num.ToStr(dummy, Num#DEC)) TV.Str(string(", Audio_output_Cog =")) dummy := v.start(@aa, 10, 11, 4_500_000) - 1 TV.Str(Num.ToStr(dummy, Num#DEC)) v.set_attenuation(0) v.set_pace(100) vp := 48 vr := 1 repeat dummy := midiIn.event if dummy <> -1 midiOut.fifoset(dummy) TV.Str(Num.ToStr(dummy, Num#HEX7)) if dummy == $903064 Seven elseif (dummy & $FFFF00) == $B00000 v.set_pace( 2 * (dummy & $00007F)) elseif (dummy & $FFFF00) == $B00100 vp := dummy & $00007F elseif (dummy & $FFFF00) == $B00200 vr := dummy & $00007F PRI Seven setformants(470,1650,2500,3500) gp := 100 ff := 180 v.go(10) fa := 40 v.go(150) fa := 0 aa := 25 v.go(100) ga := 70 setformants(700,1750,2500,3500) v.go(70) setformants(700,1500,2400,3400) v.go(150) setformants(600,1440,2300,3300) v.go(50) ga := 10 aa := 0 ff := 250 v.go(20) fa := 10 v.go(20) v.go(80) fa := 0 v.go(20) ga := 70 aa := 15 setformants(500,1440,2300,3300) v.go(20) setformants(550,1750,2400,3400) v.go(60) v.go(50) setformants(250,1700,2300,3400) setnasal(2000) na := $FF v.go(60) ga := 60 v.go(150) ga := 0 aa := 0 v.go(80) na := 0 v.go(500) PRI set(i) f1 := (f1s[i] + jj/2) / jj f2 := (f2s[i] + jj/2) / jj f3 := (f3s[i] + jj/2) / jj f4 := (f4s[i] + jj/2) / jj PRI setformants(sf1,sf2,sf3,sf4) f1 := (sf1 + jj/2) / jj <# 255 f2 := (sf2 + jj/2) / jj <# 255 f3 := (sf3 + jj/2) / jj <# 255 f4 := (sf4 + jj/2) / jj <# 255 PRI setnasal(f) nf := (f + jj/2) / jj <# 255 DAT ' byte aa,ga,gp,vp,vr,f1,q1,f2,q2,f3,q3,f4,q4,fn,qn,fa,ff note byte 0,2,4,5,7,9,11,12,11,9,7,5,4,2,0,0 s1 byte '0,0,0,0,0,670/jj,qx1,1033/jj,qx2,2842/jj,qx3,3933/19,qx4,0,0,0,0,0,0 s2 byte 40,000,100,0,0,0/16,2300/16,3000/16,3500/16,255,2000/16,0,0,0 s3 byte 20,200,100,0,0,250/16,2300/16,3000/16,3500/16,0,0,0,0,0 s4 byte 20,200,100,0,0,250/16,2300/16,3000/16,3500/16,0,0,0,0,0 s5 byte 40,200,100,5,20,700/16,1800/16,2550/16,3500/16,0,0,0,0,0 s6 byte 00,000,100,0,0,425/16,1000/16,2400/16,3500/16,0,0,0,0,0 ' ee i e a o oh foot boot r l uh f1s long 0280,0450,0550,0700,0775,0575,0425,0275,0560,0560,0700 f2s long 2040,2060,1950,1800,1100,0900,1000,0850,1200,0820,1300 f3s long 3040,2700,2600,2550,2500,2450,2400,2400,1500,2700,2600 f4s long 3600,3570,3400,3400,3500,3500,3500,3500,3050,3600,3100 q1s byte $9A, $9A, $9A, $9A, $9A, $9A, $9A, $9A, $9A, $9A, $98 q2s byte $98, $98, $98, $98, $98, $98, $98, $98, $98, $98, $96 q3s byte $94, $94, $94, $94, $94, $94, $94, $94, $94, $94, $94 q4s byte $92, $92, $92, $92, $92, $92, $92, $92, $92, $92, $90音声合成のパラメータ制御側の、1-2分で作ったMax/MSPパッチの画面は以下である。 動作確認のためのMIDI送信・受信機能も残してあるが、 ここでは
としてみると、画面内のスライダによって、面白いほどに「セブン」の発音が変化した。 上のデモでは、defaultとしてvibrate speed = 1 (もっとも低速の変化)であり、 さらにvibrate pitch = 48 とそこそこの変化幅としてあったので、 時間的に長い変化をしていたのも確認できた。 vibrate speed = 0 によって平坦な音声となり、その音域はvibrate pitchによって変化した。
- 「90 30 64」のノートオンメッセージで「セブン」の発音をスタートする
- 「B0 00 **」のコントロールチェンジ(の2倍の値)で発音のスピードを制御
- 「B0 01 **」のコントロールチェンジでvibrate pitchを制御
- 「B0 02 **」のコントロールチェンジでvibrate speedを制御
具体的に「セブン」と発音しているのは、以下の部分である。 これだけ時系列として色々と生成させて、ようやく「セブン」一発である。 発音スピードのパラメータを著しく小さくすると、 「セーーーブーーーンー」と数秒かけて発音することも可能であるが、 この場合、MIDIで次の発音スタートが来ても、全てFIFOバッテァに積まれて待たされる。 発音が終わると、バッファに溜まっていれば次の発音がスタートした。
PRI Seven setformants(470,1650,2500,3500) gp := 100 ff := 180 v.go(10) fa := 40 v.go(150) fa := 0 aa := 25 v.go(100) ga := 70 setformants(700,1750,2500,3500) v.go(70) setformants(700,1500,2400,3400) v.go(150) setformants(600,1440,2300,3300) v.go(50) ga := 10 aa := 0 ff := 250 v.go(20) fa := 10 v.go(20) v.go(80) fa := 0 v.go(20) ga := 70 aa := 15 setformants(500,1440,2300,3300) v.go(20) setformants(550,1750,2400,3400) v.go(60) v.go(50) setformants(250,1700,2300,3400) setnasal(2000) na := $FF v.go(60) ga := 60 v.go(150) ga := 0 aa := 0 v.go(80) na := 0 v.go(500) PRI setformants(sf1,sf2,sf3,sf4) f1 := (sf1 + jj/2) / jj <# 255 f2 := (sf2 + jj/2) / jj <# 255 f3 := (sf3 + jj/2) / jj <# 255 f4 := (sf4 + jj/2) / jj <# 255 PRI setnasal(f) nf := (f + jj/2) / jj <# 255基本的には、声道・鼻腔などの共鳴モデルにノイズを突っ込んで、 ディジタルフィルタ?によって実際の人間の声の発音を正直にシミュレートしているようだ。 「v.go(150)」などのように、goメソッドに与えた時間(フレーム)だけ、 その時点での13種類のパラメータでの発音が音素断片として生成され、 これが割り込み無しに補間連結されることで音声と知覚されるのだ。 Propellerアセンブラによる処理ライブラリを呼び出すspinの側だけに限って言えば、 この例のように、今後も改造と活用は容易であるらしい。
2008年3月21日(金)
exp013.spinで、とりあえずPropellerでサウンド(スピーチ)が出た。 ただし、オーディオ出力の肝心の部分、D/A変換出力をどうやっているか、 については、呼ばれる側のライブラリ、ここでは VocalTract.spin の中を解析していく必要がある。 音声合成よりも、こちらに興味があるのだが、なかなかトリッキーなアセンブラライブラリで、 解読はかなり困難である。 ちょっと後退するようでも、VocalTract.spinのサブセットを別に作って少しずつ変更し、 それをMainの側からいろいろ叩いて実験する、という方針をとった。まず、音声合成の検証ソフトとして完成した昨日のexp013.spinについてはそのままとして、 実験用のMainとしてexp013.spinをコピーしてリネームしたexp014.spinを作って一部改造、 またVocalTract.spinをコピーしてリネームしたAudioOut01.spinをさらに作って、 自分なりに改造しつつ、解読と理解を目指すことにした。 このVocalTract.spinの冒頭の解説には、Cogは最大の80MHzクロックが必要、 そしてオーディオレートは20KHzとあった。 音声であれば十分だが、これはぜひ、44.1KHzに改造したい。 またD/A変換は「デルタ変調」なので、外部回路はRCフィルタだけでいいのだと言う。
テレビのサブキャリアに音声をFMで乗せるには別のCogを必要とするらしいが、 今回は関係ないので、まずはこれに関係した部分をカットした。 パラメータについては、それぞれ固有のラベルを付けるのでなく、 ストラクチャとして定義したエリアをいきなりオフセット指定で呼び出しているので、 ちょっとの変更でも、動作は異常となって無表示/無音どころかハングアップする。 手探りで少しずついじりながらコンパイルして「まだ同等」(発音動作する)を確認する、 という繰り返しとなった。 Propeller ToolのF10で簡単にコンパイル・ダウンロードが実行でき、 Max/MSPからMIDI経由でテストトリガを簡単に出せる、 という環境でなければとても出来ない、地道な作業である。
まず以下の最初の初期化部分で、いくつか新しい記述があったので、Propellerマニュアルで確認した。
'If delta-modulation pin(s) enabled, ready output(s) and ready ctrb for duty mode if pos_pin > -1 dira_[pos_pin >> 5 & 1] |= |< pos_pin ctrb_ := $18000000 + pos_pin & $3F if neg_pin > -1 dira_[neg_pin >> 5 & 1] |= |< neg_pin ctrb_ += $04000000 + (neg_pin & $3F) << 9アナログ出力のピンは、デルタ変調としてCRTBを「duty mode」にする、 という記述は後に検討するとして、入出力ピンの定義部分、
dira_[pos_pin >> 5 & 1] |= |< pos_pin である。他のコーディングでも同じ処理は実現できそうだが、見たことのないシンボルがいくつも出て来た。 まず
dira_[pos_pin >> 5 & 1] |= |< pos_pin の「|<」である。 これは「Bitwise : Decode value (0-31) into single-high-bit long」という演算子とある。 つまりここでは、右側のpos_pinに指定したピン番号に対して、 そのビットだけ1が立ったバイナリを左側に返すデコーダ、というわけだ。 これに対して、「|>」というのもある。 これは逆にバイナリをエンコードしてlongを返すもので、spinはこんなものも提供しているのか。 次に
dira_[pos_pin >> 5 & 1] |= |< pos_pin の「|=」である。 これは「Bitwise OR」演算子とあった。 つまり、DIRAの指定したビットだけ立てることで、そのピンを出力と指定しているわけである。 ここでさらに、
dira_[pos_pin >> 5 & 1] |= |< pos_pin の部分に困ってしまった。 演算子の優先順位は「>>」と「&」ではビットシフトの方が強いので、 これはまず「pos_pin >> 5」とするが、ピン番号は0から31なので5ビットもシフトすれば0になる。 どうやらこれは、将来的にPropellerが64ポート対応になった場合のものだった。 ポート32-63の場合には、ここに1が立つことで、ビットセットの対象はdira_[1]、すなわちdirb_[0]となる。 実際、
dira_[0] |= |< pos_pin としても動作は変わらず、さらに
dira_ |= |< pos_pin でも変わらなかった。 dira_というシンボルに悩んだが、 これはもちろん、DIRAではなくてdira_という変数であり、初期化ルーチンの中で、 ここにセットした設定値をDIRAに転送する、と後に判明した。
そして以下のように、このライブラリは見るからに、かなりトリッキーな構造であることが判明してきた。 まず、対象となる、一部整理したAudioOut01.spinの冒頭の該当部分を抜き出すと以下のようになる。
VAR long cog, tract, pace long index, attenuation, sample '3 longs ...must long dira_, dirb_, ctra_, ctrb_, zzzzz, cnt_ '6 longs ...be long frames[frame_buffer_longs] 'many longs ...contiguous PUB start(parameters, pos_pin, neg_pin) dira_ |= (|< pos_pin + |< neg_pin) ctrb_ := $18000000 + pos_pin & $3F ctrb_ += $04000000 + (neg_pin & $3F) << 9 tract := parameters cnt_ := clkfreq / 20_000 return cog := cognew(@entry, @attenuation) DAT entry org :zero mov reserves,#0 'zero all reserved data add :zero,d0 djnz clear_cnt,#:zero ・・・・・・・・ mov t1,par 'get dira/dirb/ctra/ctrb add t1,#2*4 mov t2,#4 :regs rdlong dira,t1 add t1,#4 add :regs,d0 djnz t2,#:regs add t1,#4 'get cnt ticks rdlong cnt_ticks,t1 mov cnt_value,cnt 'prepare for initial waitcnt add cnt_value,cnt_ticksまず、VAR領域について、
VAR long cog, tract, pace long index, attenuation, sample '3 longs ...must long dira_, dirb_, ctra_, ctrb_, zzzzz, cnt_ '6 longs ...be long frames[frame_buffer_longs] 'many longs ...contiguousという「zzzzz」は、不要なのでカットしたテレビ音声用の変数の部分であるが、 これを削除すると動作しなくなった。 コメントにあるように、ここの変数定義は、その並びと総数もクリチカルであった。 そして、謎だった「dira_」というlong変数は、VAR領域の中で、 その2つ前には「attenuation」という変数が定義されている。 ここにヒントがあった。 このライブラリが起動時に呼ばれるメソッド「start」に注目すると、
PUB start(parameters, pos_pin, neg_pin) dira_ |= (|< pos_pin + |< neg_pin) ctrb_ := $18000000 + pos_pin & $3F ctrb_ += $04000000 + (neg_pin & $3F) << 9 tract := parameters cnt_ := clkfreq / 20_000 return cog := cognew(@entry, @attenuation)とある。 コマンドCOGNEWがアセンブラを呼ぶ場合のオプションは、 「COGNEW (AsmAddress, Parameter)」とあり、第2パラメータを渡すことが出来る。 これにより、アセンブラにはDAT領域の先頭アドレスとともに、 VAR領域の変数「attenuation」のアドレスが引渡された。 これを受け取るのが、アセンブラの初期化ルーチンの中の
mov t1,par 'get dira/dirb/ctra/ctrb add t1,#2*4 mov t2,#4 :regs rdlong dira,t1 add t1,#4 add :regs,d0 djnz t2,#:regsである。 PropellerマニュアルのPARを見ると、 「COGINITまたはCOGNEWでboot-upされた際に渡されたパラメータ」とあった。 つまり、このループの最初には、
mov t1,par 'get dira/dirb/ctra/ctrb add t1,#2*4 rdlong dira,t1という処理を行っている。 VAR領域にある「attenuation」のアドレスをlong変数t1に格納し、 ここに2(long)*4(byte)、つまり2つだけ後ろのlong変数とすることで、 目的の「dira_」が指定された。 これをrdlong命令によってDIRAに読み込むことで、 出力ポートのdirectionをセットしている。
しかし、トリッキーなプログラミングはまだ続いている。 「mov t2,#4」と「djnz t2,#:regs」によって、 以下のループは4度、回るのであるが、なかなかこれが凄いことになっている。
mov t1,par 'get dira/dirb/ctra/ctrb add t1,#2*4 mov t2,#4 :regs rdlong dira,t1 add t1,#4 add :regs,d0 djnz t2,#:regs読み込み元のアドレス(t1)を移動させる事については、1longで4bytesサイズなので、 「add t1,#4」としてループごとにアドレスに4を加える。ここは問題ない。 問題は、rdlongでの読み込み先のアドレスの移動である。 「add :regs,d0」というステートメントには、こんな意味は無い。 だいたい「:regs」というのはラベルなので、ここにあるのは 「rdlong dira,t1」というステートメントそのものである。 また、加えるオフセットについては、ソースの別の場所に
' Defined Data tune long $66920000 'scale tuned to 110.00Hz at gp=100 (manually calibrated) ・・・・・・・・ d0 long $00000200 'destination/source field increments d0s0 long $00000201と記述されていた。Propellerでは、1long(32bits)にインストラクションを格納するため、 source領域については9ビットまでしか数値を定義できないので、 「$0200」のような大きな定数は、このようにlong領域に定義する必要がある。
こうなると、Propellerマニュアルのアランブラのリファレンスの中で、 コードをバイナリで分解した解説が必要となってくる。 「rdlong」のところには、

と記載されている。 1long(32bits)のインストラクションそのものを32ビットデータと見て、 ここに、オフセット「d0」に定義された$0200を加算する、ということは、
000010 001i 1111 ddddddddd sssssssss と
000000 0000 0000 000000001 000000000 との加算、ということになる。 これはつまり、下図のPropeller内部RAMの冒頭のレジスタにおいて、 さっきはアドレス$1F6のDIRAをアクセスしていたのに対して、 destination address(ddddddddd)だけがインクリメントされて、 次のアドレス$1F7のDIRBをアクセスする、という事である。 これがt2に入った定数「#4」だけ繰り返されることで、 Propellerの共有領域に定義されたデータをCog内に、まさに「get dira/dirb/ctra/ctrb」できる。
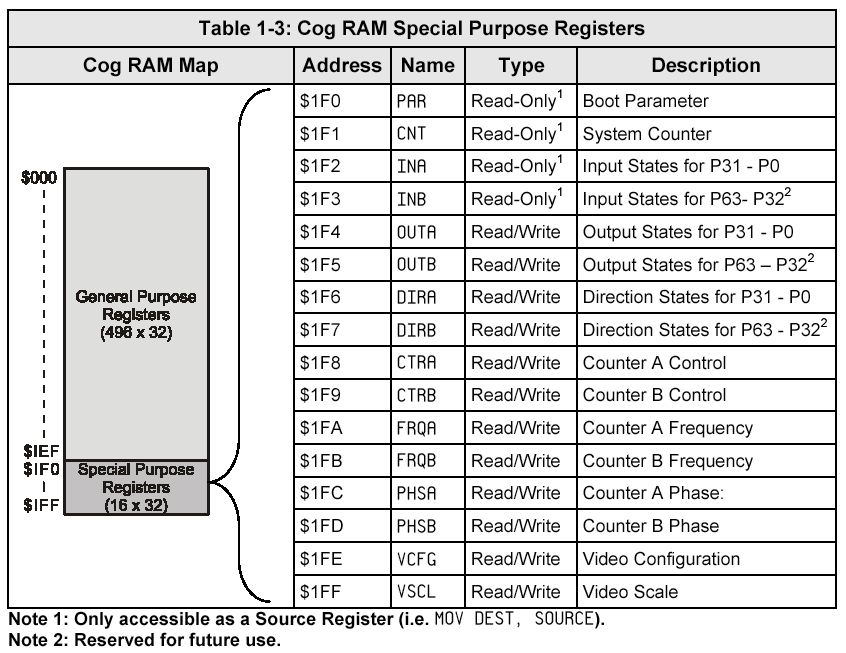
Propellerのプログラムは全て(外部EEPROMに置かれた場合も含めて)、 Propellerの内部RAMに転送され、さらに各Cogのプログラムは各Cog内のRAMに転送される。 そこでこの例のように、そのインストラクション内に含まれた、 アクセス対象アドレスの部分だけをインクリメントして書き換える、 などという芸当が実現できることになる。 「組み込みCPUのプログラムはROMに」という業界の常識とはまさに正反対である。 限られたRAMを活用するテクニック、と言えばそれまでだが、 「既に使用されたプログラムの領域は書き換えて再利用できる」というのは、 まさに発想の転換である。素晴らしい。
2008年3月22日(土)
なかなかオーディオのD/A出力の部分に到達しないまま、 サンプルの音声合成プログラムをMIDI対応版・パラメータ可変版に改造したものを、 以下のように整理してまとめてみた。 このセットで、かなり広範な「セブン」の音声合成を実験することができる。exp014.spinではこれらの他に、Propellerライブラリにあるdefaultのまま、 Numbers.spinおよびTV_Terminalというオブジェクトも呼び出している。 またTV_Terminalはさらに内部的に、TV.spinおよびGraphics.spinというオブジェクトも呼び出している。
- メイン exp014.spin
- 音声合成・サウンド出力 AudioOut01.spin
- MIDI入力 MidiIn03.spin
- MIDI出力 MidiOut01.spin
- 実験用パラメータ送信Max/MSPパッチ MIDItest01.mxt
以上のように整理したところで、 実験用のMainとしてexp014.spinをコピーしてリネームしたexp015.spinを作り、 またAudioOut01.spinをコピーしてリネームしたAudioOut02.spinを作って、 機能を残しつつさらにシンプルに整理して、全体の解読と理解を目指すことにした。 まず最初に、
OBJ Num : "Numbers" TV : "TV_Terminal" midiIn : "MidiIn03" midiOut : "MidiOut01" v[4] : "AudioOut02"のOBJブロックの定義の中で、
v[4] : "AudioOut02" とある配列は、v[2]でもv[1]でも動作か変わらない事を確認して、最終的に
v : "AudioOut02" とした。 これは、4声のポリフォニーのデモのために、最大で同時発音を4音(4 Cogs)にする、 というものであり、当面は1ボイス(1 Cog)で十分だからである。 次に、
CON frame_buffers = 8 'frame buffers (2保n) frame_bytes = 3 {for stepsize} + 13 {for aa..ff} '16 bytes per frame frame_longs = frame_bytes / 4 '4 longs per frame frame_buffer_bytes = frame_bytes * frame_buffers frame_buffer_longs = frame_longs * frame_buffersの中のframe_buffersの数値を変えてみた。 8を16にしても32にしても、当然ながら動作は変化しなかった。 逆に4、2、そして1にしても、ここでは単音であるからか、動作は同じであった。 そこで単純化のために、frame_buffers = 1として、CONブロックを以下のようにした。
CON frame_buffers = 1 frame_bytes = 16 frame_longs = 4 frame_buffer_bytes = 16 frame_buffer_longs = 4この条件の元では、発音合成の音素ごとに呼ばれる
PUB go(time) repeat while frames[index] bytemove(@frames[index] + 3, tract, 13) frames[index] |= $01000000 / (time * 100 / pace #> 2) index := (index + frame_longs) & constant(frame_buffer_longs - 1)のうち、最後のステートメントの
index := (index + frame_longs) & constant(frame_buffer_longs - 1) は、indexに4を加えても、3とANDを取れば再び0になるので、 indexは0から変化しないことになる。 よってここを「index := 0」と書き換えて、動作が変わらないことを確認した。
frames[4]と定義されているので、indexの値は0から3までは変化するように思えたが、 パラメータが16バイトあるためであり、バッファを最小サイズにした場合には、 indexでアクセスする事は無くなるので、変数indexの初期化を省略し、indexを0に置き換えた。 これにより、発音スタートで呼ばれるメソッドの動きは、
PUB go(time) repeat while frames[0] bytemove(@frames[0] + 3, tract, 13) frames[0] |= $01000000 / (time * 100 / pace #> 2)となり、まずはframes[0]がノンゼロである間は、ここで足踏みして待つ。 実際、あるセグメントが発音中は、新しい発音スタートを受け付けずバッファに溜まって、 発音が終わると次に続く。 この先頭の1long(4bytes)の下位3バイトは、後述の時間データであり、 上位1バイト(4バイト目)は発音パラメータの「breath volume」とある。 これが全てゼロとならないと、以前の発音の処理が終わらないとして次に入らない。 フレームデータの先頭4バイトがゼロで「処理OK」となると、 ここには4longs(16bytes)のエリアがあるが、その先頭3バイトをスキップして、 4バイト目から13バイトにわたって、「tract」で指定されている13バイトを、 frames[0]の後半13bytesに転送している。 このtractは、
VAR long cog, tract, pace long index, attenuation, sample '3 longs ...must long dira_, dirb_, ctra_, ctrb_, zzzzz, cnt_ '6 longs ...be long frames[frame_buffer_longs] 'many longs ...contiguous PUB start(parameters, pos_pin, neg_pin) dira_ |= (|< pos_pin + |< neg_pin) ctrb_ := $18000000 + pos_pin & $3F ctrb_ += $04000000 + (neg_pin & $3F) << 9 tract := parameters cnt_ := clkfreq / 20_000 return cog := cognew(@entry, @attenuation)とあるので、呼び出し元の親メソッドから、第一パラメータとして渡されているアドレスである。 これは、呼び出し側では
VAR long stackspace[40] byte aa,ga,gp,vp,vr,f1,f2,f3,f4,na,nf,fa,ff byte jj PUB Main | dummy Num.Init TV.Start(12) TV.Str(string("Audio_output_Cog =")) dummy := v.start(@aa, 10, 11) TV.Str(Num.ToStr(dummy, Num#DEC)) v.set_attenuation(0) v.set_pace(100) vp := 48 vr := 1 jj := 19とあるので、まさに音声合成パラメータの13個のbyte変数を並べた、 その先頭アドレスを引渡している。 これによって、親メソッドのパラメータは子メソッドのPropellerアセンブラから参照される。 「PUB go(time)」の3行目では、frames[0]の先頭3バイトに、 発音スピードであるpaceと、発音継続時間であるtimeとに応じた時間データが初期値として格納される。 このデータは、オーディオ出力処理の無限ループの中で、 刻々とディクリメントされる(ゼロになれば発音完了、次の発音可能)らしい。
これでAudioOut02.spinの冒頭部分は、CONブロックも消えて以下のようにスッキリとして、 さらにここまでは、不明な部分が無くなった。
VAR long cog, tract, pace, index, attenuation, sample '6 longs ...must long dira_, dirb_, ctra_, ctrb_, zzzzz, cnt_ '6 longs ...be long frames[4] 'many longs ...contiguous PUB start(parameters, pos_pin, neg_pin) dira_ |= (|< pos_pin + |< neg_pin) ctrb_ := $18000000 + pos_pin & $3F ctrb_ += $04000000 + (neg_pin & $3F) << 9 tract := parameters cnt_ := clkfreq / 20_000 return cog := cognew(@entry, @attenuation) PUB set_attenuation(level) attenuation := level PUB set_pace(percentage) pace := percentage PUB go(time) repeat while frames[0] bytemove(@frames[0] + 3, tract, 13) frames[0] |= $01000000 / (time * 100 / pace #> 2)これを受けて、続いてDATブロックの先頭にある、Propellerアセンブラの初期化部分を調べた。 startメソッドから呼ばれる、ラベルentryからの、以下の領域である。
DAT entry org :zero mov reserves,#0 'zero all reserved data add :zero,d0 djnz clear_cnt,#:zero mov t1,#2*15 'assemble 15 multiply steps into reserves :minst mov mult_steps,mult_step '(saves hub memory) add :minst,d0s0 test t1,#1 wc if_c sub :minst,#2 djnz t1,#:minst mov mult_ret,antilog_ret 'write 'ret' after last instruction mov t1,#13 'assemble 13 cordic steps into reserves :cstep mov t2,#8 '(saves hub memory) :cinst mov cordic_steps,cordic_step add :cinst,d0s0 djnz t2,#:cinst sub :cinst,#8 add cordic_dx,#1 add cordic_dy,#1 add cordic_a,#1 djnz t1,#:cstep mov cordic_ret,antilog_ret 'write 'ret' over last instruction mov t1,par 'get dira/dirb/ctra/ctrb add t1,#2*4 mov t2,#4 :regs rdlong dira,t1 add t1,#4 add :regs,d0 djnz t2,#:regs add t1,#4 'get cnt ticks rdlong cnt_ticks,t1 mov cnt_value,cnt 'prepare for initial waitcnt add cnt_value,cnt_ticksこれに対応するのは、以下の変数領域確保の部分である。 基本的にはここにパラメータをセットするが、Propellerならではの部分もありそうだ。
reserves 'reserved registers that get cleared on startup frqa_center res 1 cnt_ticks res 1 cnt_value res 1 frame_index res 1 frame_ptr res 1 frame_cnt res 1 step_size res 1 step_acc res 1 vphase res 1 gphase res 1 fphase res 1 f1x res 1 f1y res 1 f2x res 1 f2y res 1 f3x res 1 f3y res 1 f4x res 1 f4y res 1 nx res 1 a res 1 x res 1 y res 1 t1 res 1 t2 res 1 par_curr '*** current parameters aa res 1 'aspiration amplitude ga res 1 'glottal amplitude gp res 1 'glottal pitch vp res 1 'vibrato pitch vr res 1 'vibrato rate f1 res 1 'formant1 frequency f2 res 1 'formant2 frequency f3 res 1 'formant3 frequency f4 res 1 'formant4 frequency na res 1 'nasal amplitude nf res 1 'nasal frequency fa res 1 'frication amplitude ff res 1 'frication frequency par_next res 13 '*** next parameters par_step res 13 '*** parameter steps mult_steps res 2 * 15 'assembly area for multiply steps w/ret mult_ret sine_ret res 1 cordic_steps res 8 * 13 - 1 'assembly area for cordic steps w/ret cordic_ret res 1順に確認していくと、まず最初の
:zero mov reserves,#0 'zero all reserved data add :zero,d0 djnz clear_cnt,#:zeroの部分は、定数を定義する領域で
clear_cnt long $1F0 - reserves 'number of reserved registers to clear on startup とあるので、変数領域の先頭ラベルであるreservesから、 内部レジスタ的なメモリ($1F0)まで全部、とわかる。 ここでも、
:zero mov reserves,#0 'zero all reserved data
というステートメントが、「自分自身を書き換える命令」となっていく。 まずは先頭のreservesという変数に初期値の#0が入る。 続く「add :zero,d0」というのは、昨日あったように、d0というのは$200という定数である。 これを、上のステートメントのあるラベル「:zero」に加えると、
000010 001i 1111 ddddddddd sssssssss と
000000 0000 0000 000000001 000000000 との加算となり、命令としては「1アドレスだけ、mov先が移動」したことになる。 このループを、「djnz clear_cnt,#:zero」命令によってclear_cnt回、ループするので、 結果として、「reservesからの変数全てを0で初期化」が行われる。 これに続いて
mov t1,#2*15 'assemble 15 multiply steps into reserves :minst mov mult_steps,mult_step '(saves hub memory) add :minst,d0s0 test t1,#1 wc if_c sub :minst,#2 djnz t1,#:minst mov mult_ret,antilog_ret 'write 'ret' after last instructionの部分が、この初期化での重要なところとなる。 まずt1に2*15=30という定数がセットされ、 reservesのブロックの最後付近に
mult_steps res 2 * 15 'assembly area for multiply steps w/ret と 2*15=30 longs定義されたmult_stepsを転送先と設定する。 転送元は、プログラムの中で
・・・・ ' Multiply ' in: t1 = unsigned multiplier (15 top bits used) ' t2 = signed multiplicand (17 top bits used) ' out: t1 = 32-bit signed product mult shr t1,#32-15 'position unsigned multiplier sar t2,#15 'position signed multiplicand shl t2,#15-1 jmp #mult_steps 'do multiply steps mult_step sar t1,#1 wc 'multiply step that gets assembled into reserves (x15) if_c add t1,t2 ' Cordic rotation ' in: a = 0 to <90 degree angle (~13 top bits used) ' x,y = signed coordinates ' out: x,y = scaled and rotated signed coordinates cordic sar x,#1 'multiply (x,y) by %0.10011001 (0.60725 * 0.984) mov t1,x '...for cordic pre-scaling and slight damping ・・・・と置かれたラベルである。 このラベルの位置の1longのステートメントが、転送先mult_stepsのオフセット[0]にコピーされる。 続く「add :minst,d0s0」のソース加算値は、
d0s0 long $00000201 と定義されている。 これは、
000010 001i 1111 ddddddddd sssssssss と
000000 0000 0000 000000001 000000001 との加算ということで、命令としては「1アドレスだけ、mov元と、mov先とを移動」することになる。 ソースもディスティネーションも同時に変化させよう、という事である。 ただしここでは、
test t1,#1 wc if_c sub :minst,#2が入っているので、デクリメントされるt1のLSBをキャリーに入れて、 つまり1バイトおきに「sub :minst,#2」と、minst、 すなわちこのコード内部のソース部分「sssssssss」でせっかく2つ進んだアドレスを元に戻している。 実はここは、「ビットシフトと加算による乗算」ルーチンなのだが、 プログラムとして15回も、「ビットシフトと加算」を無駄に並べて置きたくない、という事のようだ。 つまり、本来のプログラム(Propellerの共有RAM)では、乗算を構成するための要素として、
mult_step sar t1,#1 wc 'multiply step that gets assembled into reserves (x15) if_c add t1,t2のたった2行だけを費やしている。 そしてCog内のRAMにmult_stepsという(2*15=30 longs)場所を用意して、 この初期化を実行した結果としては、内部的に
mult_steps sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2 sar t1,#1 wc if_c add t1,t2という乗算演算サブルーチンが用意できたことになるのである。 これに続く
mov mult_ret,antilog_ret 'write 'ret' after last instruction によって、この新しく作られたルーチンの戻りアドレスは、 アンチログ演算の出口と共通になったことになり、 ここに記述されている「ret」によってリターンする。 その格納先のmult_retは、変数確保としては「res 1」 すら省略して、 次のsine_retと共用している。 無駄は極限まで省いて、最大の効率を上げられるのだ、というPropellerの美学すら感じさせる。
これに続くのは、「Cordic rotation」というルーチンの初期化である。 CODECかと思ったらCORDICということで 調べてみる と、
CORDIC (digit-by-digit method, Volder's algorithm) (for COordinate Rotation DIgital Computer) is a simple and efficient algorithm to calculate hyperbolic and trigonometric functions. It is commonly used when no hardware multiplier is available (e.g., simple microcontrollers and FPGAs) as the only operations it requires are addition, subtraction, bitshift and table lookup.とあった。 要するに、三角関数の演算を、データテーブルと単純な繰り返し演算で実現する手法のようである。 これは今後も使えるものだろう。 このCORDICのためには、cordic_delta long $4B901476 'cordic angle deltas (first is h80000000) long $27ECE16D long $14444750 long $0A2C350C long $05175F85 long $028BD879 long $0145F154 long $00A2F94D long $00517CBB long $0028BE60 long $00145F30 long $000A2F98と角度のデルタ値を13通りに定数で定義するとともに、
cordic_steps res 8 * 13 - 1 'assembly area for cordic steps w/ret cordic_ret res 1とかなりのエリアを確保していて、以下のように2重ループで回して転送している。
mov t1,#13 'assemble 13 cordic steps into reserves :cstep mov t2,#8 '(saves hub memory) :cinst mov cordic_steps,cordic_step add :cinst,d0s0 djnz t2,#:cinst sub :cinst,#8 add cordic_dx,#1 add cordic_dy,#1 add cordic_a,#1 djnz t1,#:cstep mov cordic_ret,antilog_ret 'write 'ret' over last instructionこの転送ループでの処理は、転送元にある8行の以下の処理を1ブロックとすると、 少しずつパラメータを変えた13ブロックのサブルーチンとして、 Propellerの内部RAMに展開して確保したことになる。
cordic_step mov a,a wc 'cordic step that gets assembled into reserves (x13) mov t1,y cordic_dx sar t1,#1 '(source incremented for each step) mov t2,x cordic_dy sar t2,#1 '(source incremented for each step) sumnc x,t1 sumc y,t2 cordic_a sumnc a,cordic_delta '(source incremented for each step)「mov cordic_ret,antilog_ret」によって、CORDIC処理のリターンも共通の場所にある「ret」となった。 これに続くのは、既に調べた以下のPropellerレジスタの初期化だった。 今となっては、これが簡単に見えるから不思議である。
mov t1,par 'get dira/dirb/ctra/ctrb add t1,#2*4 mov t2,#4 :regs rdlong dira,t1 add t1,#4 add :regs,d0 djnz t2,#:regsそして初期化の最後の部分には、以下が続いている。
add t1,#4 'get cnt ticks rdlong cnt_ticks,t1 mov cnt_value,cnt 'prepare for initial waitcnt add cnt_value,cnt_ticksこのt1は、直前にctrb_の次のzzzzzを示していたので、ここで#4を加えるとcnt_を示す。 ここには「cnt_ := clkfreq / 20_000」と、 オーディオ処理レートに対応したクロック値が定義されていたので、 これをCog内部のRAMのcnt_ticksにロードした。 これに続く2行は、その後の「Vocal Tract Loop」という、 サンプリング周期ごとのバックグラウンド(無限ループ)処理のための時間の設定である。 これで、初期化についても、その意味が全てクリアになった。 あまりにトリッキーと言えばそうだし、アランブラの極致と言えばそうである。
次はいよいよ、20KHzのサンプリング周期ごとに行っている処理の部分である。 20KHzということは50μsecである。 Propellerのクロックは80MHzであり、Cog内部の命令は4クロックないし8クロックなので、 4クロックだと20MHzで50nsec、これでサンプリング周期ごとに最大1000命令である。 ただしPropeller内部の共用RAMをrdlong/wrlong命令でアクセスすると、 自分のCogに番が回ってくるまで最大22クロック必要なので、 このあたりはまさに、プログラミングの腕の見せ所だろう。
実際、「cnt_ := clkfreq / 20_000」の20_000を10_000と半分(10KHz)にしてみると、 サンプリングが半分になった、オクターブ下の音声がした。 ところが30_000(30KHz)とすると、まったく帰ってこなくなった。 そこで少しずつ試してみると、25KHzでも21KHzでも駄目、 なんとか出たのは20.2KHzまでだった。 かなり、指折り数えて、ギリギリまでチューニングされたライブラリらしい。
さて、その以下のルーチンはかなり長大である。 さらに途中でサインや乗算やアンチログやCORDICのサブルーチンをCALLしている。 とりあえず最後のブロックのあたりに、フレームインデックスの処理があるようだが、 これは単一フレームに単純化しているので、このあたりから攻めるしかなさそうである。
' Vocal Tract Loop ' Wait for next sample period, then output sample loop waitcnt cnt_value,cnt_ticks 'wait for sample period rdlong t1,par 'perform master attenuation sar x,t1 mov t1,x 'update duty cycle output for pin driving add t1,h80000000 mov frqb,t1 mov t1,par 'update sample receiver in main memory add t1,#1*4 wrlong x,t1 :White_noise_source test lfsr,lfsr_taps wc 'iterate lfsr three times rcl lfsr,#1 test lfsr,lfsr_taps wc rcl lfsr,#1 test lfsr,lfsr_taps wc rcl lfsr,#1 :Aspiration mov t1,aa 'aspiration amplitude mov t2,lfsr call #mult sar t1,#8 'set x mov x,t1 :Vibrato mov t1,vr 'vibrato rate shr t1,#10 add vphase,t1 mov t1,vp 'vibrato pitch mov t2,vphase call #sine add t1,gp 'sum glottal pitch (+) into vibrato pitch (+/-) :Glottal_pulse shr t1,#2 'divide final pitch by 3 to mesh with mov t2,t1 '...12 notes/octave musical scale shr t2,#2 '(multiply by %0.0101010101010101) add t1,t2 mov t2,t1 shr t2,#4 add t1,t2 mov t2,t1 shr t2,#8 add t1,t2 add t1,tune 'tune scale so that gp=100 produces 110.00Hz (A2) call #antilog 'convert pitch (log frequency) to phase delta add gphase,t2 mov t1,gphase 'convert phase to glottal pulse sample call #antilog sub t2,h40000000 mov t1,ga call #sine sar t1,#6 'add to x add x,t1 :Vocal_tract_formants mov y,#0 'reset y mov a,f1 'formant1, sum and rotate (x,y) add x,f1x add y,f1y call #cordic mov f1x,x mov f1y,y mov a,f2 'formant2, sum and rotate (x,y) add x,f2x add y,f2y call #cordic mov f2x,x mov f2y,y mov a,f3 'formant3, sum and rotate (x,y) add x,f3x add y,f3y call #cordic mov f3x,x mov f3y,y mov a,f4 'formant4, sum and rotate (x,y) add x,f4x add y,f4y call #cordic mov f4x,x mov f4y,y :Nasal_anti_formant add nx,x 'subtract from x (nx negated) mov a,nf 'nasal frequency call #cordic mov t1,na 'nasal amplitude mov t2,x call #mult mov x,nx 'restore x neg nx,t1 'negate nx :Frication mov t1,lfsr 'phase noise sar t1,#3 add fphase,t1 sar t1,#1 add fphase,t1 mov t1,ff 'frication frequency shr t1,#1 add fphase,t1 mov t1,fa 'frication amplitude mov t2,fphase call #sine add x,t1 'add to x jmp :ret 'run segment of frame handler, return to loop :ret long :wait 'pointer to next frame handler routine :wait jmpret :ret,#loop '(6 or 17.5 cycles) mov frame_ptr,par 'check for next frame add frame_ptr,#8*4 'point past miscellaneous data add frame_ptr,frame_index 'point to start of frame rdlong step_size,frame_ptr 'get stepsize and step_size,h00FFFFFF wz 'isolate stepsize and check if not 0 if_nz jmp #:next 'if not 0, next frame ready mov :final1,:finali 'no frame ready, ready to finalize parameters mov frame_cnt,#13 'iterate aa..ff :final jmpret :ret,#loop '(13.5 or 4 cycles) :final1 mov par_curr,par_next 'current parameter = next parameter add :final1,d0s0 'update pointers djnz frame_cnt,#:final 'another parameter? jmp #:wait 'check for next frame :next add step_size,#1 'next frame ready, insure accurate accumulation mov step_acc,step_size 'initialize step accumulator movs :set1,#par_next 'ready to get parameters and steps for aa..ff movd :set2,#par_curr movd :set3,#par_next movd :set4,#par_step add frame_ptr,#3 'point to first parameter mov frame_cnt,#13 'iterate aa..ff :set jmpret :ret,#loop '(19.5 or 46.5 cycles) rdbyte t1,frame_ptr 'get new parameter shl t1,#24 'msb justify :set1 mov t2,par_next 'get next parameter :set2 mov par_curr,t2 'current parameter = next parameter :set3 mov par_next,t1 'next parameter = new parameter sub t1,t2 wc 'get next-current delta with sign in c negc t1,t1 'make delta absolute (by c, not msb) rcl vscl,#1 wz, nr 'save sign into nz (vscl unaffected) mov t2,#8 'multiply delta by step size :mult shl t1,#1 wc if_c add t1,step_size djnz t2,#:mult :set4 negnz par_step,t1 'set signed step add :set1,#1 'update pointers for next parameter+step add :set2,d0 add :set3,d0 add :set4,d0 add frame_ptr,#1 djnz frame_cnt,#:set 'another parameter? :stepframe jmpret :ret,#loop '(47.5 or 8 cycles) mov :step1,:stepi 'ready to step parameters mov frame_cnt,#13 'iterate aa..ff :step jmpret :ret,#loop '(3 or 4 cycles) :step1 add par_curr,par_step 'step parameter add :step1,d0s0 'update pointers for next parameter+step djnz frame_cnt,#:step 'another parameter? add step_acc,step_size 'accumulate frame steps test step_acc,h01000000 wc 'check for frame steps done if_nc jmp #:stepframe 'another frame step? sub frame_ptr,#frame_bytes 'zero stepsize in frame to signal frame done wrlong vscl,frame_ptr add frame_index,#frame_bytes'point to next frame and frame_index,#frame_buffer_bytes - 1 jmp #:wait 'check for next frame :finali mov par_curr,par_next 'instruction used to finalize parameters :stepi add par_curr,par_step 'instruction used to step parametersちょっと長いが、要するに冒頭の
loop waitcnt cnt_value,cnt_ticks 'wait for sample period でサンプリング周期まで足踏みして、ここからとりあえず
・・・・・・・・
jmp :ret 'run segment of frame handler, return to loopの前までは、一直線に、そのセグメントでの音声合成パラメータによる演算を行っている。 実際、試しに最初のwaitcntをもう1回、ただ無駄に重ねて、
としてみると、サンプリング周期が半分になったような、 オクターブ下の音声となった。 これだけの演算を行えるというのは大変なもので、これが複数のCogsで同時に出来る、 というのは、Propeller恐るべし、と言えるだろう。loop waitcnt cnt_value,cnt_ticks 'wait for sample period waitcnt cnt_value,cnt_ticks ・・・・・・・・2008年3月23日(日)
さて昨日の続きである。jmp :ret 'run segment of frame handler, return to loop の前までの演算処理に続く、 最後の部分、以下の3行がちょっと変わっている。 ここは一連の処理が終わった部分で、
jmp :ret 'run segment of frame handler, return to loop :ret long :wait 'pointer to next frame handler routine :wait jmpret :ret,#loop '(6 or 17.5 cycles)となっている。 JMPの先の「:ret」の場所で、ラベルである「:wait」がlong定義されているようなので、 ここを「jmp :wait」としてもよさそうかな・・・と変更してみると、 サウンドが出ないだけでなく、最初の発音イベントから親オブジェクトに帰ってこなくなった。 かなりクリチカルである。
ここで、PropellerマニュアルのJMPコマンドとJMPRETコマンドについて調べた。 JMPというはのは文字通りの無条件ジャンプなので、 オペランドフィールドのアドレスにジャンプするだけである。 ここではラベルによってCog内のRAM(:ret)が指定されているが「#」が無いので、 「そのRAM(:ret)に入っている値をアドレスと見なしてそこにジャンプ」という事になる。
その「:ret」には、「long :wait」とあるので、ジャンプ先の指定は「:wait」である。 それではここを「jmp #:wait」としてもよさそうかな・・・と変更してみると、 サウンドが出ないだけでなく、最初の発音イベントから親オブジェクトに帰ってこなくなった。 なかなかクリチカルである。(^_^;)
ラベル「:wait」にあるコードは、
jmpret :ret,#loop である。JMPRETというのは見慣れないが、マニュアルには以下のように書かれている。
JMPRETPropellerにはCallスタックという概念が無いので、JMPはともかく、 CALLについてはかなり不思議な動作をする。 CALL命令を実行する際には、CogはそのCALL先のラベルに対して、RETの置かれた「ラベル_RET」を探す。 そしてRET(これはPropellerではJMPの一種)のsourceフィールドに、CALL命令の直後のアドレスを書き込んで、 CALL先にJMPする。 CALL先では、最後にRETがあれば、これを書き換えられたJMPとして実行することで、 CALLの置かれた場所の次のインストラクションに戻って来るのだという。 実際、RETとJMPのインストラクションビット(opcode)は一致している。Instruction: Jump to address with intention to “return” to another address.
JMPRET RetInstAddr, <#>DestAddress
Result: PC + 1 is written to the s-field of the register indicated by the d-field.
Explanation
- RetInstAddr (d-field) is the register in which to store the return address (PC + 1); it should be the address of an appropriate RET or JMP instruction for DestAddress.
- DestAddress (s-field) is the register or 9-bit literal whose value is the address to jump to.
JMPRET stores the address of the next instruction (PC + 1) into the source field of the instruction at RetInstAddr, then jumps to DestAddress. The routine at DestAddress should eventually execute the RET or JMP instruction at the RetInstAddr to return to the stored address (the instruction following the JMPRET).
The Propeller does not use a call stack, so the return address must be stored at the location of the routine’s RET, or returning JMP, command itself. JMPRET is a superset of the CALL instruction; in fact, it is the same opcode as CALL but the i-field and d-field configured by the developer, rather than the assembler.
The return address is written to the RetInstAddr register unless the NR effect is specified.
Propellerマニュアルには、CALLというのはJMPRETのサブセットである、と書かれていた。 実際、


というように両者を比較してみると、JMPRETでイミディエイト指定(アドレスを#で直接指定)した場合には、 両者のインストラクションビット(opcode)は完全に一致する。 そこでJMPRETというのはJMPの一種というより、 「その次の行き先まで指定するジャンプ」というCALLの一種である、と考える必要がある。
CALLではデスティネーションが「?????????」となっていたが、 JMPRETでは、次のライン(PC+1)のインストランションのアドレスを、 dddddddddフィールドの「RetInstAddr」に格納する。 書式にある「JMPRET RetInstAddr, <#>DestAddress」のRetInstAddrが「次の行き先(戻り先)」であり、 <#>DestAddressがとりあえずのJMP先である。 従ってここでは、とりあえずの行き先は、Vocal Tract Loopの先頭の「loop」である。 そしてRetInstAddrにはこのJMPRET命令の次のアドレスが書き込まれるので、 行った先でRETかJMPによってそこに戻るのだという。
この例では、「loop」からの一連の処理の中で、何度も数値演算のルーチンもCALLしていて、 そこにあるRETはCALL地点に戻るので、動作がどうもすっきりしない。 そこでまず、見やすくするために、以下のように、loopのwaitcntの命令の次から、 一連の音声合成パラメータ処理を行って、「jmp :ret」の前までの一連のブロックを切り出して、 「sampling_job」というラベルでプログラム部分の末尾に移動して、 その最後に「sampling_job_ret」というラベルでret命令を置いた。 「frame_」→「f_」など、一部のラベルも簡略化した。
' Main Loop - Wait for next sample period, then output sample loop waitcnt cnt_value,cnt_ticks 'wait for sample period call #sampling_job jmp :ret 'run segment of frame handler, return to loop :ret long :wait 'pointer to next frame handler routine :wait jmpret :ret,#loop '(6 or 17.5 cycles) mov f_ptr,par 'check for next frame add f_ptr,#8*4 'point past miscellaneous data add f_ptr,f_index 'point to start of frame ・・・・・・・・ ' Vocal Tract Job sampling_job rdlong t1,par 'perform master attenuation sar x,t1 mov t1,x 'update duty cycle output for pin driving add t1,h80000000 ・・・・・・・・ mov t2,fphase call #sine add x,t1 'add to x sampling_job_ret retもちろんこれでも、まだ音声合成の動作は同様に実行された。 ここで謎なのは、これまで一度も出てこなかった「:ret long :wait」である。 Propellerマニュアルを調べても、アランブラコードにlongという命令は無く、 これはやはり、アセンブラのデータ領域でのlong定数定義である、と解釈するしかない。
そこで、さらにPropellerマニュアルのCALLとJMPRETの説明を詳細に読み解いてみた。 CALLの戻り先は、CALLインストラクションの次(PC+1)である。 それを格納するのは、「ラベル_ret」の置かれた場所のRETステートメントであり、 その場所がCALLのデスティネーション領域にエンコードして書き込まれる。 実行されて行き先にRETがあれば、そこにはCogによって(PC+1)が書かれているので、 無条件ジャンプで戻って来る。
JMPRETの戻り先については、dddddddddフィールドの「RetInstAddr」に、 JMPRETインストラクションの次(PC+1)を格納するのだが、 このRetInstAddrには、イミディエイトの#アドレスは指定できないことを、 コンパイル実験のエラーで確認した。 そこで#アドレスではなく、メモリ(レジスタ)を指定して、 その内容が参照されて、行き先にRETがあればそこに無条件ジャンプする。 これは既に初期化ルーチンで見たように、同じ行き先にジャンプしながら、 戻る場所を動的に書き換える、という機能を実現できる可能性がある。
ここでの場合には、DestAddressは「#loop」とイミディエイト指定しているので、 インストラクションビット(opcode)はCALLと一致している。 RetInstAddrには「:ret」とあるので、Cog内RAMのこのアドレスに戻り先(PC+1)を格納する。 その「:ret」にはとりあえずlong定義として「:wait」が置かれている。 いちばん最初に「jmp :ret」を実行すると、これによって「:wait」の場所に飛ぶ。
「:ret」の行の前後に、また「:wait」の行の前後に、ラベルを付けたNOPなどを入れて、 「ret: long :ラベル」と試行錯誤してみたところ、 それでも動作は変わらなかった。そして、なんとこの部分を「long :wait」から
jmp :ret 'run segment of frame handler, return to loop :ret long :ret 'pointer to next frame handler routine :wait jmpret :ret,#loop '(6 or 17.5 cycles)と書き換えても、動作が変わらないことを発見した。 ただし、「:ret」の行に単に「long 0」とか、long定義でなく「NOP」とかを置いても駄目で、 他の場所のラベルを置いてもまったく駄目だった。 まとめると、
loop waitcnt cnt_value,cnt_ticks 'wait for sample period call #sampling_job :ng nop jmp :ret 'run segment of frame handler, return to loop :ok1 nop :ret long :ok2 'pointer to next frame handler routine :ok2 nop :wait jmpret :ret,#loop '(6 or 17.5 cycles)で、「:ret long :ok2」の「ok2」の部分をいろいろ替えて実験し、 得た結論は
ということになる。 なんとなく、この付近を示す場合にだけOKのようである。
- 動作が変わらず正常 - ok1 / ret / ok2 / wait
- 異常で帰らない - ng / 他のラベル / 他の場所
ここでようやく、状況が理解できた。 確認するために、初期化ルーチンのブロックをブロックを切り出して、 「initial」というラベルでプログラム部分の末尾に移動して、 その最後に「intial_ret」というラベルでret命令を置いた。 また、loopから始まる一連の処理は、最後の「jmp :ret」というところまでを切り出して、 プログラム部分の後半に移動した。 ただしローカルラベルの「:ret」はこの移動でローカルを越えてエラーとなったので、 プログラム全体の「:ret」を「retadd」と変更した。 そして、以下のようにしてみると、これでも動作が確認できた。
焦点の部分を抜き出すと、ここは以下のような構造になっている。
- メイン exp015.spin
- 音声合成・サウンド出力 AudioOut02.spin
DAT entry org call #initial jmp #loop retadd long :wait 'pointer to next frame handler routine :wait jmpret retadd,#loop '(6 or 17.5 cycles) mov f_ptr,par 'check for next frame add f_ptr,#8*4 'point past miscellaneous data ・・・・・・・・ :final jmpret retadd,#loop '(13.5 or 4 cycles) ・・・・・・・・ jmp #:wait 'check for next frame ・・・・・・・・ :set jmpret retadd,#loop '(19.5 or 46.5 cycles) ・・・・・・・・ :stepframe jmpret retadd,#loop '(47.5 or 8 cycles) ・・・・・・・・ :step jmpret retadd,#loop '(3 or 4 cycles) ・・・・・・・・ jmp #:wait 'check for next frame ・・・・・・・・ ' Vocal Tract Job loop waitcnt cnt_value,cnt_ticks 'wait for sample period rdlong t1,par 'perform master attenuation ・・・・・・・・ add x,t1 'add to x jmp retadd 'run segment of frame handler, return to loop
「retadd long :***」というのは、ここにJMPRETのリターンアドレスを格納する場所、 という定義である。 この後の一連の処理では、何度も「jmpret retadd,#loop」というコードが登場する。 これはPropellerのシステムにおいては、「CALL #loop」の意味であり、 このコードの次の場所(PC+1) に戻ってくる、という使い方である。 その戻り場所の格納先として、ここでは「retadd」の領域が定義されている。
そこで、さきの実験の「jmp :ret」の結果としては、 アドレス「:ret」の中身が「:ret long :ret」「:ret long :wait」「:ret long :dummy1」 のいずれの場合にも、Cog内アドレス(最大$1FF)として32ビット表現では上位15ビットはゼロであり、 これはインストラクションとしてはNOPと解釈される。 続くアドレスについても同様なので、処理はJMPRETのラインに至る。
Propellerの特殊性であるが、JMPRETというのはCALLのスーパーセットである。 JMPというのも、ある意味ではRETのスーパーセットなのだった。 このあたりに慣れる必要があるが、とりあえず、理解はだいぶ進展した。
2008年3月24日(月)
CALLとJMPRETにだいぶ苦労したので、まだまだ解析は途中である。 ここで、実験用のMainとしてexp015.spinをコピーしてリネームしたexp016.spinを作り、 またAudioOut012.spinをコピーしてリネームしたAudioOut03.spinを作って、 少しずつ改造・削減しながら、さらなる解読と理解を目指した。次に表れるのは、フレームごとにステップで分割して補間演算していく、 と思われる処理である。 その最初の部分は以下である。
mov f_ptr,par 'check for next frame add f_ptr,#8*4 'point past miscellaneous data rdlong step_size,f_ptr 'get stepsize and step_size,h00FFFFFF wz 'isolate stepsize and check if not 0 if_nz jmp #:next 'if not 0, next frame ready mov :final1,:finali 'no frame ready, ready to finalize parameters mov f_cnt,#13 'iterate aa..ff :final jmpret retadd,#loop '(13.5 or 4 cycles) :final1 mov par_curr,par_next 'current parameter = next parameter add :final1,d0s0 'update pointers djnz f_cnt,#:final 'another parameter? jmp #:wait 'check for next frameこの最初の部分には、既に初期化のところで見覚えがある。
mov f_ptr,par 'check for next frame add f_ptr,#8*4 'point past miscellaneous data rdlong step_size,f_ptr 'get stepsizeまず変数f_ptrに、レジスタparの中身を転送する。 PARはPropellerの内部RAMのアドレス「$1F0」のBoot Parameterなので、 startメソッドから渡された@attenuation、つまりVAR変数attenuationのアドレスである。 ここに8longs分のオフセットを加えるということは、
VAR long cog, tract, pace, index, attenuation, sample '6 longs ...must long dira_, dirb_, ctra_, ctrb_, zzzzz, cnt_ '6 longs ...be long frames[4] 'many longs ...contiguousの定義から、ちょうど8変数だけスキップして、変数f_ptrの中身はframes[0]の先頭になる。 ここは3バイトの時間データと13バイトのパラメータが入る場所である。 このPropeller内共有RAMにある先頭long(4bytes)データを、Cog内のlong変数step_sizeに読み込む。 このステートメントは、7クロックから22クロックの間で実行される。 幅があるのは、Cogsと共有RAMとのハードウェアスイッチングで待たされるからで、 たまたまスグなら7クロック、過ぎた直後なら22クロックである。
and step_size,h00FFFFFF wz 'isolate stepsize and check if not 0 if_nz jmp #:next 'if not 0, next frame ready「and step_size,h00FFFFFF wz」というステートメントで、 変数step_sizeに取り込んだデータのうち、セグメント長の時間の設定に関する下位3バイトをマスクして、 ゼロと比較する。 このデータがゼロにならないうちは、発音処理の、該当フレーム(セグメント)の処理がまだ終了していないので、 次のフレームに進めない、ということだろう。 ノンゼロの場合の処理は「jmp #:next」に続くのだが、ここでは先に、 この時間データがゼロとなって、次のフレームに行くという、以下の処理の部分を片付ける。
mov :final1,:finali 'no frame ready, ready to finalize parameters mov f_cnt,#13 'iterate aa..ff :final jmpret retadd,#loop '(13.5 or 4 cycles) :final1 mov par_curr,par_next 'current parameter = next parameter add :final1,d0s0 'update pointers djnz f_cnt,#:final 'another parameter? jmp #:wait 'check for next frame :finali mov par_curr,par_next 'instruction used to finalize parameters最初の「mov :final1,:finali」というのは、一見すると不思議である。 転送先のラベル「:final1」にあるコードは「mov par_curr,par_next」であり、 これは転送元のラベル「:finali」にあるコード「mov par_curr,par_next」と、まったく同一である。 普通のCPUであればまったくの無駄のようだが、 実はラベル「:final1」の場所の中身は、ループとともに変化するので、 最初に飛び込むためには初期化が必要なのだった。
ここではループカウンタf_cntで13回の繰り返しがあるが、 その都度、まずはサンプリング周期を意識して「jmpret retadd,#loop」をコールしている。 「add :final1,d0s0」の増分値d0s0は$201、 すなわち9ビットデータで「000000001 000000001」なので、 このループによって、ラベル「:final1」にあるコードの内部の、 ソースとデスティネーションの部分はそれぞれ+1されるように書き換えられる。 そして、13回の後に、次のパラメータリストpar_nextが現在のパラメータリストpar_currにコピーされる。
ところでここでの実験では、変数frame_index(f_index)を最小の1にしているので、 実はnextもクソもなく、常に書き込まれたフレーム、ただ1つだけで動作しているのである。 そこで、この部分をスキップして、
and step_size,h00FFFFFF wz 'isolate stepsize and check if not 0 if_nz jmp #:next 'if not 0, next frame ready jmp #:wait mov :final1,:finali 'no frame ready, ready to finalize parameters mov f_cnt,#13 'iterate aa..ff :final jmpret retadd,#loop '(13.5 or 4 cycles) :final1 mov par_curr,par_next 'current parameter = next parameter add :final1,d0s0 'update pointers djnz f_cnt,#:final 'another parameter? jmp #:wait 'check for next frame :finali mov par_curr,par_next 'instruction used to finalize parametersすなわち
and step_size,h00FFFFFF wz 'isolate stepsize and check if not 0 if_nz jmp #:next 'if not 0, next frame ready jmp #:wait 'check for next frameとしても構わない。「:finali」の部分もカットして、これでまたスッキリした。 すると、この次には「:next」が以下のように始まっている。
プログラム中に他に「:next」を参照するところもなかったので、 これは以下のようにさらにシンプルになった。and step_size,h00FFFFFF wz 'isolate stepsize and check if not 0 if_nz jmp #:next 'if not 0, next frame ready jmp #:wait 'check for next frame :next add step_size,#1 'next frame ready, insure accurate accumulation mov step_acc,step_size 'initialize step accumulator ・・・・・・・・and step_size,h00FFFFFF wz 'isolate stepsize and check if not 0 if_z jmp #:wait 'if not 0, next frame ready add step_size,#1 'next frame ready, insure accurate accumulation mov step_acc,step_size 'initialize step accumulator ・・・・・・・・これに続くちょっと後の部分の中でも、 変数f_indexを最小の1までに限定しているので、
if_nc jmp #:stepframe 'another frame step? sub f_ptr,#frame_bytes 'zero stepsize in frame to signal frame done wrlong vscl,frame_ptr add f_index,#frame_bytes 'point to next frame and f_index,#frame_buffer_bytes - 1 jmp #:wait 'check for next frameという部分は以下のようにできる。ここの詳細は後で検討する。
まとめると、以下の部分で、フレーム中のステップの補間処理が行われているらしい。 ときどき「jmpret :ret,#loop」でサンプリング処理に行っていて、 「(19.5 or 46.5 cycles)」などと、生々しく、前回アクセスからのステップ数を計算している。 これがオーバーするとサウンドとして破綻するのだろう。 ちょっと長いが、最後の関門である。if_nc jmp #:stepframe 'another frame step? sub f_ptr,#16 'zero stepsize in frame to signal frame done wrlong vscl,f_ptr jmp #:wait 'check for next frameadd step_size,#1 'next frame ready, insure accurate accumulation mov step_acc,step_size 'initialize step accumulator movs :set1,#par_next 'ready to get parameters and steps for aa..ff movd :set2,#par_curr movd :set3,#par_next movd :set4,#par_step add f_ptr,#3 'point to first parameter mov f_cnt,#13 'iterate aa..ff :set jmpret :ret,#loop '(19.5 or 46.5 cycles) rdbyte t1,f_ptr 'get new parameter shl t1,#24 'msb justify :set1 mov t2,par_next 'get next parameter :set2 mov par_curr,t2 'current parameter = next parameter :set3 mov par_next,t1 'next parameter = new parameter sub t1,t2 wc 'get next-current delta with sign in c negc t1,t1 'make delta absolute (by c, not msb) rcl vscl,#1 wz, nr 'save sign into nz (vscl unaffected) mov t2,#8 'multiply delta by step size :mult shl t1,#1 wc if_c add t1,step_size djnz t2,#:mult :set4 negnz par_step,t1 'set signed step add :set1,#1 'update pointers for next parameter+step add :set2,d0 add :set3,d0 add :set4,d0 add f_ptr,#1 djnz f_cnt,#:set 'another parameter? :stepframe jmpret :ret,#loop '(47.5 or 8 cycles) mov :step1,:stepi 'ready to step parameters mov f_cnt,#13 'iterate aa..ff :step jmpret :ret,#loop '(3 or 4 cycles) :step1 add par_curr,par_step 'step parameter add :step1,d0s0 'update pointers for next parameter+step djnz f_cnt,#:step 'another parameter? add step_acc,step_size 'accumulate frame steps test step_acc,h01000000 wc 'check for frame steps done if_nc jmp #:stepframe 'another frame step? sub f_ptr,#16 'zero stepsize in frame to signal frame done wrlong vscl,f_ptr jmp #:wait 'check for next frame :stepi add par_curr,par_step 'instruction used to step parameters2008年3月25日(火)
さて、昨日の続きである。 まず最初の、以下の部分に問題はない。 step_sizeはディクリメントされてゼロと比較される? と思い込んでいたが、#1を加えている。 どうやらインクリメントされるらしい。 また一周したときに$00FFFFFFとANDを取るので、 オーバーフローしてもAND後の判定ではゼロとなるので、これは問題ない。 続いて、この値を「step_acc」に代入している。そして続く以下の部分には、またまた新しいステートメントが登場してきた。 Propellerならではの命令である。add step_size,#1 'next frame ready, insure accurate accumulation mov step_acc,step_size 'initialize step accumulatormovs :set1,#par_next 'ready to get parameters and steps for aa..ff movd :set2,#par_curr movd :set3,#par_next movd :set4,#par_step add f_ptr,#3 'point to first parameter mov f_cnt,#13 'iterate aa..ff :set jmpret :ret,#loop '(19.5 or 46.5 cycles) rdbyte t1,f_ptr 'get new parameter shl t1,#24 'msb justify :set1 mov t2,par_next 'get next parameter :set2 mov par_curr,t2 'current parameter = next parameter :set3 mov par_next,t1 'next parameter = new parameter sub t1,t2 wc 'get next-current delta with sign in c negc t1,t1 'make delta absolute (by c, not msb) rcl vscl,#1 wz, nr 'save sign into nz (vscl unaffected) mov t2,#8 'multiply delta by step size :mult shl t1,#1 wc if_c add t1,step_size djnz t2,#:mult :set4 negnz par_step,t1 'set signed step add :set1,#1 'update pointers for next parameter+step add :set2,d0 add :set3,d0 add :set4,d0 add f_ptr,#1 djnz f_cnt,#:set 'another parameter?ここまで来ればもう驚かないが、MOVSとは、対象のステートメントのうち、 「ソース領域の部分にだけ」転送する、というMOVである。 MOVSDとは、対象のステートメントのうち、 「デスティネーション領域の部分にだけ」転送する、というMOVである。 こんな変態的なMOV命令は他のCPUでは聞いたことがないが、 Propellerにはさらに、MOVIという、対象のステートメントのうち、 「インストラクション領域の部分にだけ」転送する、というMOVもある。
限られたCog内RAMを有効に使えるものだが、命令の一部を書き換えてしまう、 というのは、かなり革命的だと思う。 MOVSとMOVDとは、セットで一括転送に使えそうだが、MOVIとなったら、 命令そのものを書き換えて実行できてしまう。 なんとも凄いコマンド体系だ。
さっきの例と同様に、最初の
movs :set1,#par_next 'ready to get parameters and steps for aa..ff movd :set2,#par_curr movd :set3,#par_next movd :set4,#par_stepの部分は、後にある「:set1」などのステートメントの中身を、 あらためて初期化しているだけである。 これに続く
add f_ptr,#3 'point to first parameter mov f_cnt,#13 'iterate aa..ffの部分は、16バイトのパラメータのうち13個の領域の先頭のポインタにセットして、 さらにループの回数を13回(パラメータの総数)にセットしているだけである。 そして、以下がこの部分のループ本体である。
:set jmpret :ret,#loop '(19.5 or 46.5 cycles) rdbyte t1,f_ptr 'get new parameter shl t1,#24 'msb justify :set1 mov t2,par_next 'get next parameter :set2 mov par_curr,t2 'current parameter = next parameter :set3 mov par_next,t1 'next parameter = new parameter sub t1,t2 wc 'get next-current delta with sign in c negc t1,t1 'make delta absolute (by c, not msb) rcl vscl,#1 wz, nr 'save sign into nz (vscl unaffected) mov t2,#8 'multiply delta by step size :mult shl t1,#1 wc if_c add t1,step_size djnz t2,#:mult :set4 negnz par_step,t1 'set signed step add :set1,#1 'update pointers for next parameter+step add :set2,d0 add :set3,d0 add :set4,d0 add f_ptr,#1 djnz f_cnt,#:set 'another parameter?まず最初に、
:set jmpret :ret,#loop '(19.5 or 46.5 cycles) rdbyte t1,f_ptr 'get new parameter shl t1,#24 'msb justifyの「:set」の部分で、サンプリング周期の処理を一旦、コールして戻ってくる。 次に、VAR領域にあるパラメータはbyteデータなので、 rdbyteコマンドで1バイトだけ、Cog内部の変数t1に読み込む。 そしてこれを24ビット、左シフトする。内部演算は32ビットなので、 下位3バイトを切り捨て誤差としてMSBに持って来るのだろうか。 とりあえずt1の下位3バイトは全てゼロである。 これに続く
:set1 mov t2,par_next 'get next parameter :set2 mov par_curr,t2 'current parameter = next parameter :set3 mov par_next,t1 'next parameter = new parameterでは、次のセグメントpar_nextのパラメータをt2に入れて、これを現在のセグメントpar_currに入れて、 共有RAMから読み込んできたt1のパラメータ(24ビットシフトした値)を次のセグメントpar_nextのパラメータに入れている。 いずれの数値も最上位1バイトに置かれて、下位3バイトは全てゼロということになる。 そして、この次の部分にはまた目新しいコードがあった。
sub t1,t2 wc 'get next-current delta with sign in c negc t1,t1 'make delta absolute (by c, not msb) rcl vscl,#1 wz, nr 'save sign into nz (vscl unaffected)「sub t1,t2 wc」は「t1 - t2 を t1に」なので、 13種類のそれぞれのパラメータごとに「next値からcurrent値を引いてt1に」ということである。 ここでの減算は値をUnsignedとして行われる。 いずれの数値も最上位1バイトに置かれているので、結果の下位3バイトは全てゼロである。 t1はデルタ値(差分値)となり、サインビットはマイナスになった時に立つ。 その次のNEGCは、

とあった。キャリーフラグ=0 ならSValueそのものが、キャリーフラグ=1 ならSValueのAdditive Inverseが、 RValueに書き込まれるという。 Additive Inverseというのは「足してゼロになる数」である。 ここでは「negc t1,t1」と両方がt1だから、要するに直前の演算結果が負ならマイナスを付ける、 つまり「絶対値」演算の意味となる。 確かにコメントに「make delta absolute (by c, not msb)」とある。 しかし、絶対値を取るにはABSというコマンドもあるので、 別に構わないのかもしれないが、これはプチ謎である。そして次に、
sub t1,t2 wc 'get next-current delta with sign in c negc t1,t1 'make delta absolute (by c, not msb) rcl vscl,#1 wz, nr 'save sign into nz (vscl unaffected)と突然にVSCLというのが登場した。 これは「Vodeo Scale Register」($1FF)という、Cog内の特別なレジスタであり、 本来はビデオ生成に使うものであるが、汎用レジスタとしても使えるという。 しかし、このCogはビデオ生成をしないし、汎用としてもここまでVSCLなどというシンボルは登場していない。 つまり初期化も何もないレジスタを1ビット左シフトするという。 WZオプションにより、シフト結果がゼロの時にはゼロフラグを立て、 そしてNRオプションにより、シフト結果はなんとVSCLに書き込まないのだという。 これはミッド謎である。
・・・しばし考えて、ようやく見えた。プチ謎とミッド謎はセットだったのだ。 まず「sub t1,t2 wc」は、t2-t1をUnsignedで計算し、結果が負であればキャリーフラグを立てる。 そして「negc t1,t1」では、そのキャリーに応じてt1のMSB(サインビット)をゼロにするが、 同時にキャリーフラグにソース(t1)のMSBを持ってくる。 どうやらコメントの「(by c, not msb)」というのはこの意味らしい。
そして「rcl vscl,#1 wz, nr」によって、中身を変更しないVSCLを1ビット左シフトするために、 「(仮に)VSCLのLSBにキャリーを入れて1ビット左シフトしたら」の結果がゼロフラグに書かれる。 これは前段でキャリーが立っていた場合、この実行によって1となりゼロフラグがclearされ、 キャリーが立っていなければゼロなのでゼロフラグが立つことになる。 前段の実行結果には差分値があるのでSUBのWZオプションは使えず、 「キャリーフラグの反転をゼロフラグに」したいために、 このように回りくどいことをしているのだろうか。 どうやらコメントの「save sign into nz」というのはこの事で、 「キャリーフラグの反転をゼロフラグに」=「キャリーフラグをノンゼロフラグに」と解釈できる。 ノンゼロであればキャリーが立っていて、つまりマイナスという事である。
この結果がゼロフラグに書かれたまま、次にWZオプションのあるコマンドが登場するまでは、 キープされる。これも普通のCPUとは違うところである。 そして、続く以下のルーチンは、WRオプションの登場しない、単純な「乗算」である。 そういえばPropellerには、乗算/除算の命令は無いのだった。 最初の「mov t2,#8」命令により、まずは定数#8がループカウンタt2にセットされる。
mov t2,#8 'multiply delta by step size :mult shl t1,#1 wc if_c add t1,step_size djnz t2,#:mult :set4 negnz par_step,t1 'set signed stepとりあえずここだけの動作を追えば、差分値t1の下位3バイトはゼロなので、
ということで、ゼロだったt1の下位3バイト部分に、 t1のMSBが1の時だけ3バイトデータであるstep_sizeを加える、ということで、 見事に最後は「差分絶対値t1の上位1バイト * 3バイトデータのstep_size」が32ビットデータとして得られる。 ループが8回というのは、この実効8ビットのデータに起因していた。
- 差分値t1を1ビット、左シフトする
- t1からハミ出したMSBはキャリーフラグに入る
- キャリーが立てば、t1にstep_size(今日の冒頭に登場)を加える
- これを8ビット分、ループする
この結果t1は、「:set4 negnz par_step,t1」のNEGNZによって、 ゼロフラグが立っていればそのまま、 ゼロフラグがゼロならt1のAdditive Inverseがpar_stepに書き込まれる。 乗算の途中にはWZオプションは登場しなかったので、 さきにキープされていたサイン情報がここに効いてきて、 par_stepには、「差分絶対値 * step_size」のAdditive Inverseが書き込まれることになる。
これに続く以下については、もはや簡単に読めてしまう。 「add :set1,#1」では、「:set1」の場所にあるステートメント「mov t2,par_next」のソース側だけがインクリメントされ、 次のパラメータに対応する。 「:set2」「:set3」「:set4」では、加算値d0は「000000001 000000000」なので、 デスティネーションの方だけがインクリメントされ、それぞれ次のパラメータに対応する。 いずれも、コードの中の特定領域だけの書き換えというテクニックである。 パラメータ読み出しのf_ptrもインクリメントされ、 これが「djnz f_cnt」によって、13パラメータ全てに同様に回って終了する。
add :set1,#1 'update pointers for next parameter+step add :set2,d0 add :set3,d0 add :set4,d0 add f_ptr,#1 djnz f_cnt,#:set 'another parameter?最後に残ったのは、以下の部分である。
:stepframe jmpret :ret,#loop '(47.5 or 8 cycles) mov :step1,:stepi 'ready to step parameters mov f_cnt,#13 'iterate aa..ff :step jmpret :ret,#loop '(3 or 4 cycles) :step1 add par_curr,par_step 'step parameter add :step1,d0s0 'update pointers for next parameter+step djnz f_cnt,#:step 'another parameter? add step_acc,step_size 'accumulate frame steps test step_acc,h01000000 wc 'check for frame steps done if_nc jmp #:stepframe 'another frame step? sub f_ptr,#16 'zero stepsize in frame to signal frame done wrlong vscl,f_ptr jmp #:wait 'check for next frame :stepi add par_curr,par_step 'instruction used to step parametersこれはもはや、以下同文で大部分が片付く。 「:stepi」のラインを初期化でコピー(再設定)して、またまたパラメータ数の13回をループする。 「:step1」への加算値d0s0は「000000001 000000001」なので、 ソースとスティネーションの両方がインクリメントされ、それぞれ次のパラメータに対応する。 ループの中身は、
:step1 add par_curr,par_step 'step parameterである。 つまり、par_currの中身に、すぐ上で計算された、 符号付きの「差分絶対値 * step_size」が加算される。 これは、パラメータが増加しても減少しても対応しているわけである。
これに続いて、
add step_acc,step_size 'accumulate frame steps test step_acc,h01000000 wc 'check for frame steps done if_nc jmp #:stepframe 'another frame step?の部分では、インクリメントされたstep_sizeを累算値step_accに加えて、 累算結果が24ビットを越えたかどうかを調べている。 オーバーしていればこのフレームの処理が終わったということで、以下に続く。
sub f_ptr,#16 'zero stepsize in frame to signal frame done wrlong vscl,frame_ptr jmp #:wait 'check for next frameここではフレームインデックスを1としたので、ここはほとんど無意味である。 「sub f_ptr,#16」でポインタはパラメータエリアの先頭に戻る。 そしてここではフレームの処理が終わったということで、 たまたま初期値のゼロから変化していないVSCLを使って、 パラメータエリアのframe[0]をゼロクリアした、という事である。 これで、プログラムの基幹部分については、全て調べたことになる。
ここまでのところを整理すると、このプログラムでは、
というところである。 まだ全部は見ていないが、結局、ここまでには、Propellerの出力ピンからサウンドを出す、 という肝心の部分のヒントは何も見えてこない。 しかし、Propellerのアセンブラの特異性については、十分に堪能できた。
- 発音スタートが来るとパラメータの先頭3バイトのstep_sizeに時間を設定する
- 親オブジェクトからの音声合成13パラメータはpar_nextに格納される
- 実際の発音処理はpar_currの領域の13パラメータのデータを使用する
- サンプリングの合間にstep_sizeごとにパラメータを補間演算する
- パラメータ補間は現在値par_currと目標値par_nextとの間で行う
- それぞれのパラメータ補間の符号付きデルタ値はpar_stepにある
ここで、改めてこれまでを眺めてみて、大きなミスがあったことに気付いた。 たまたま偶然にも、初期化のstartメソッドの所で、ビット演算子と呼び出しパラメータ渡しに気を取られていて、 「'If delta-modulation pin(s) enabled, ready output(s) and ready ctrb for duty mode」 と書かれた以下の2行について、まったく触れずに飛ばしていた。
PUB start(parameters, pos_pin, neg_pin) dira_ |= (|< pos_pin + |< neg_pin) ctrb_ := $18000000 + pos_pin & $3F ctrb_ += $04000000 + (neg_pin & $3F) << 9 tract := parameters cnt_ := clkfreq / 20_000 return cog := cognew(@entry, @attenuation)実はこれこそ、Propellerでサウンドを出力するためのヒントだったのである。 そして、全体を見やすくするために、「音声合成パラメータについての一連の処理」ということで、 プログラムの後半にブロックとして移動させてサブルーチンコールしていた部分に、 まさにこれとペアになる命令を発見した。 いよいよ明日から、この核心に直撃だ。

Propeller日記(4) へ
「日記」シリーズ の記録