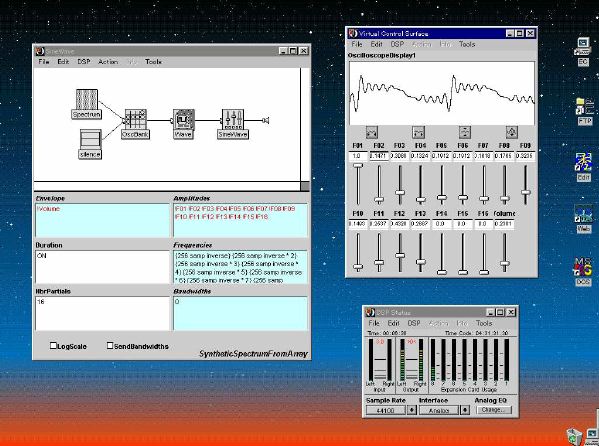
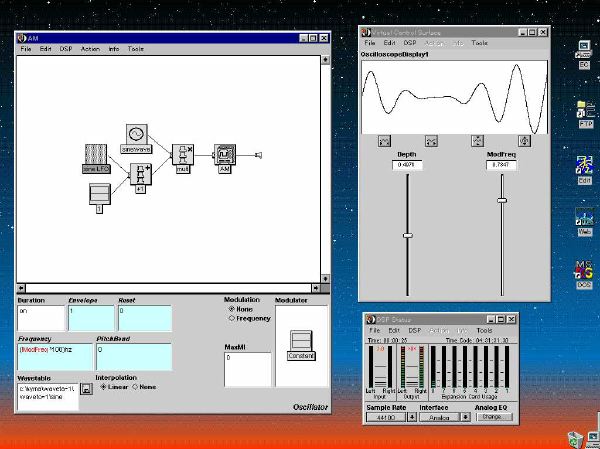
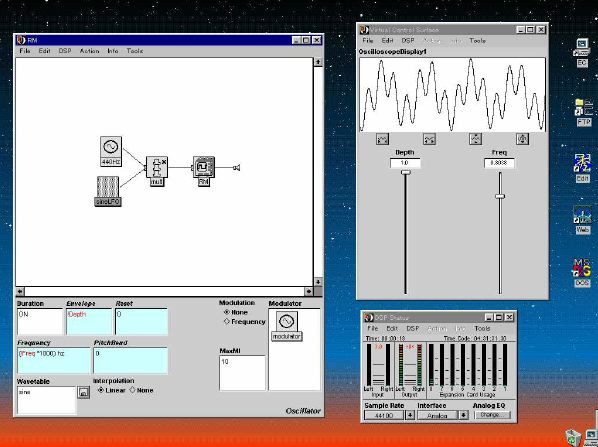
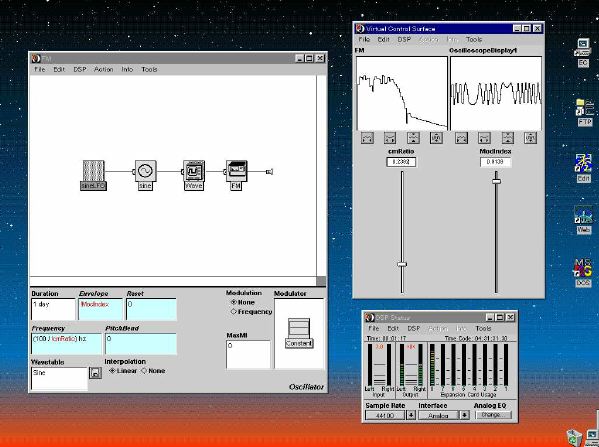
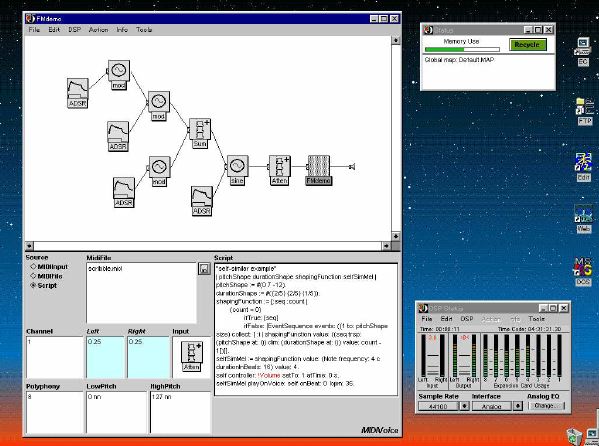
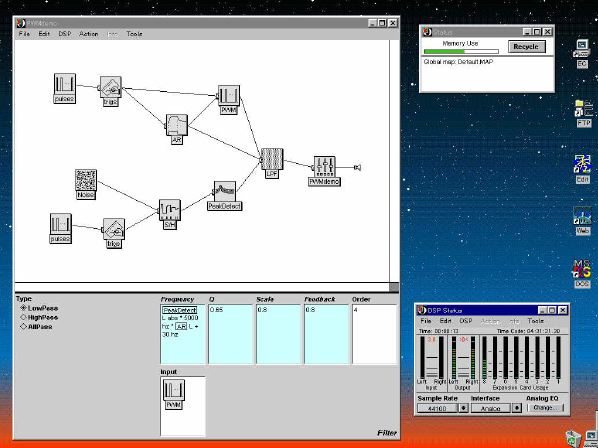
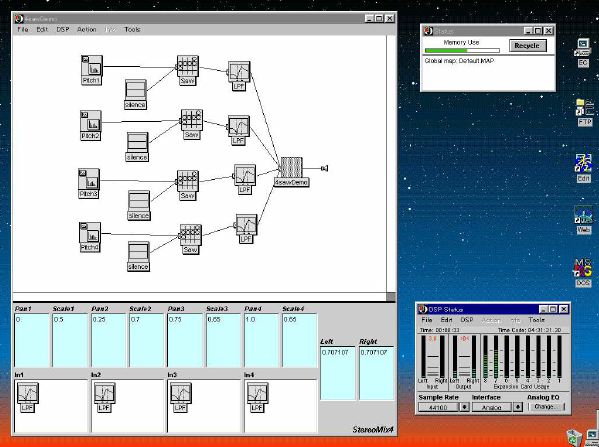
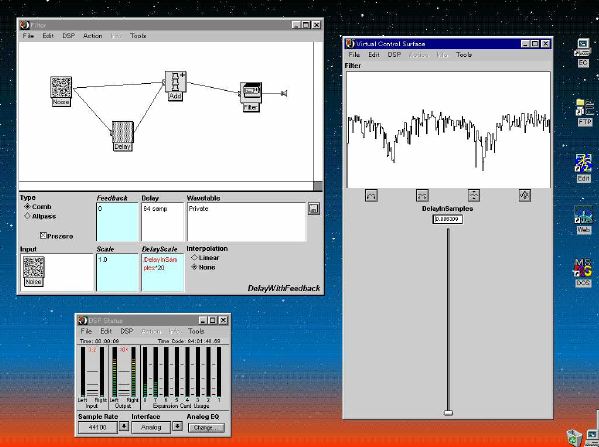
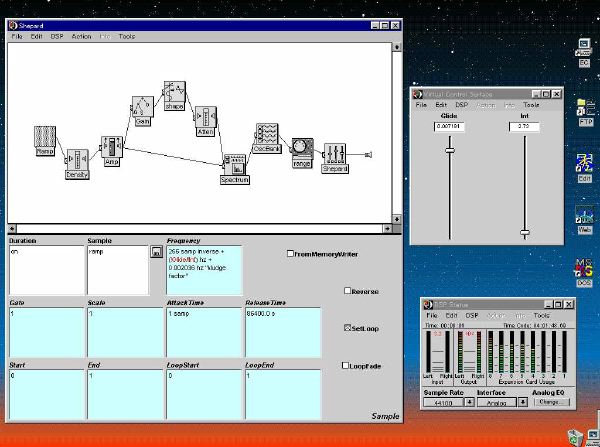
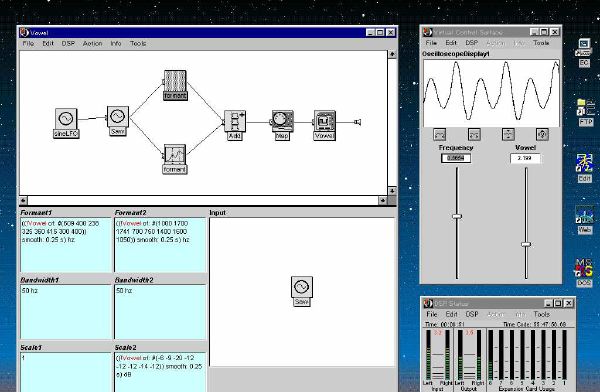
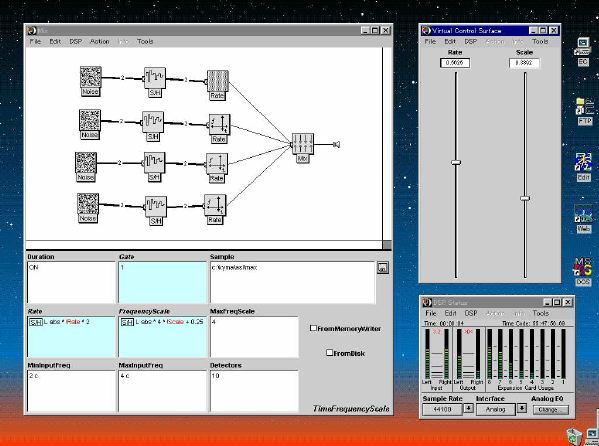
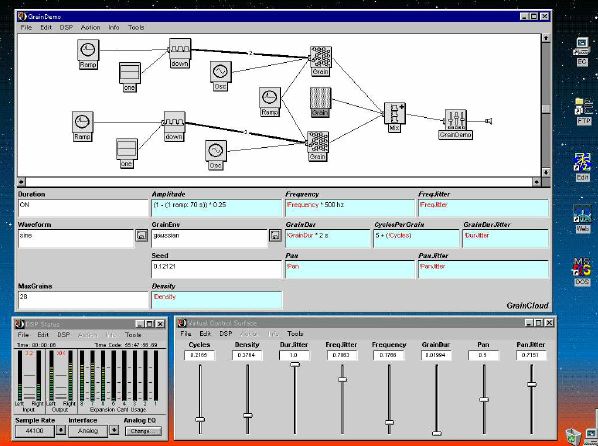
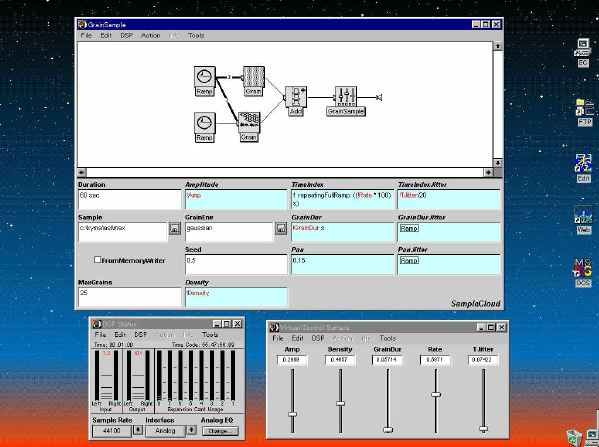
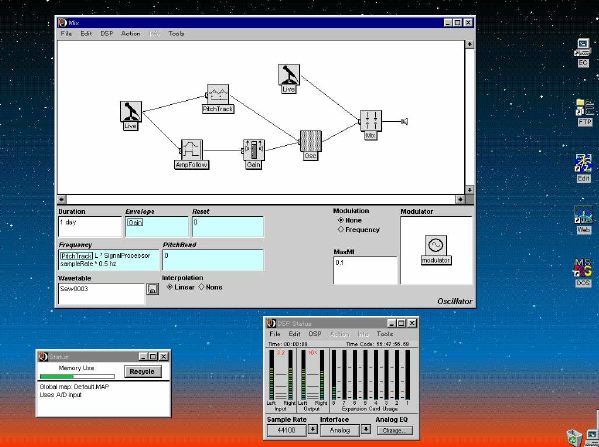
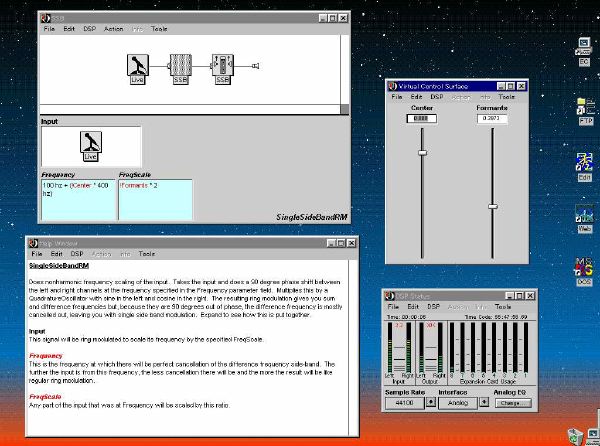
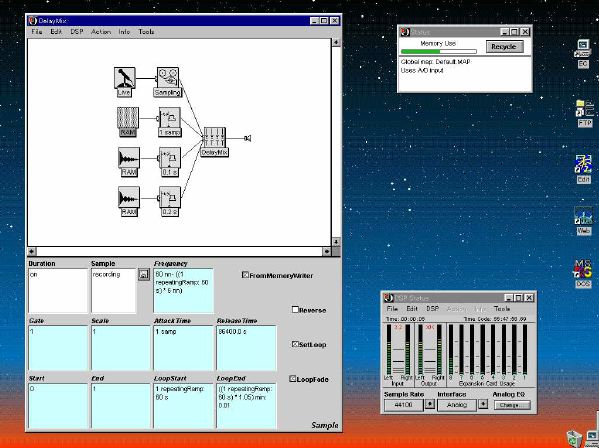
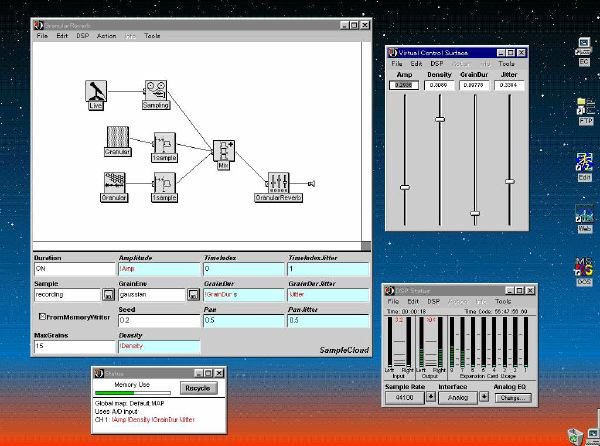
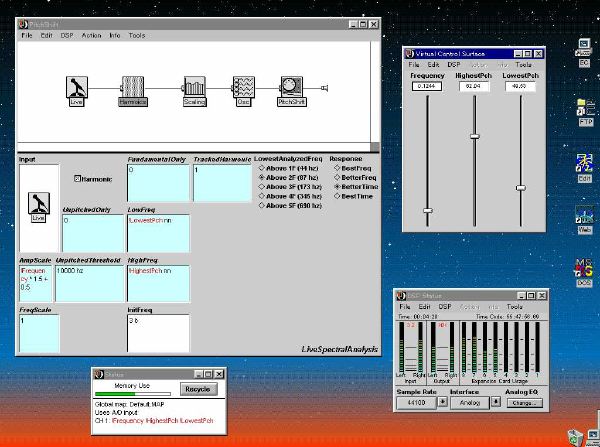
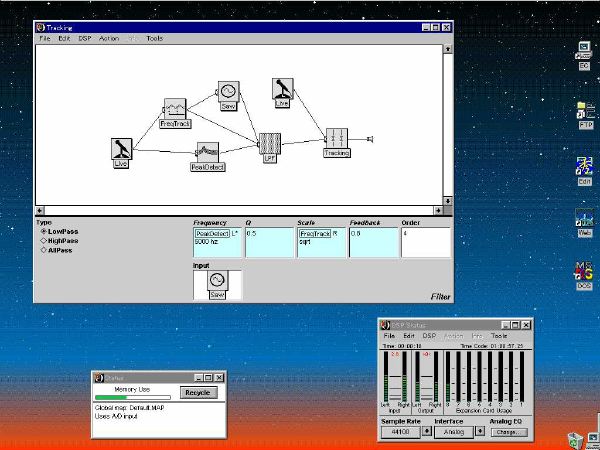
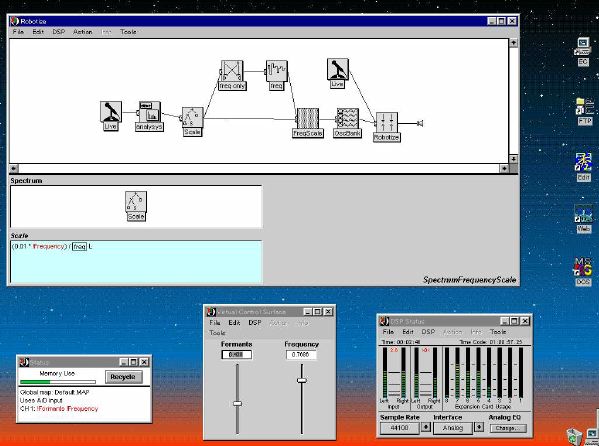
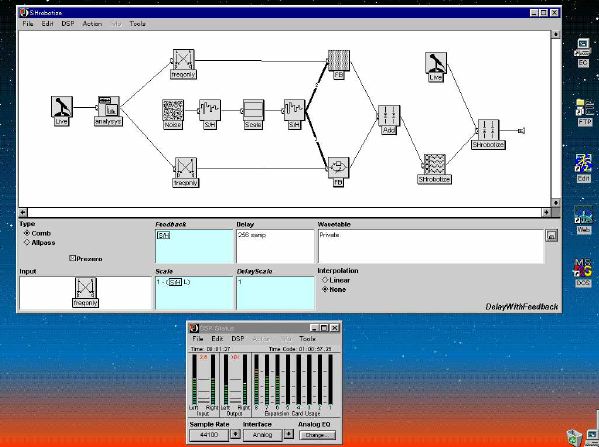
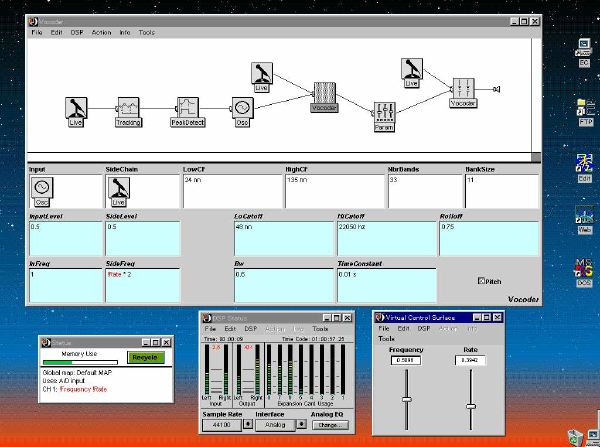
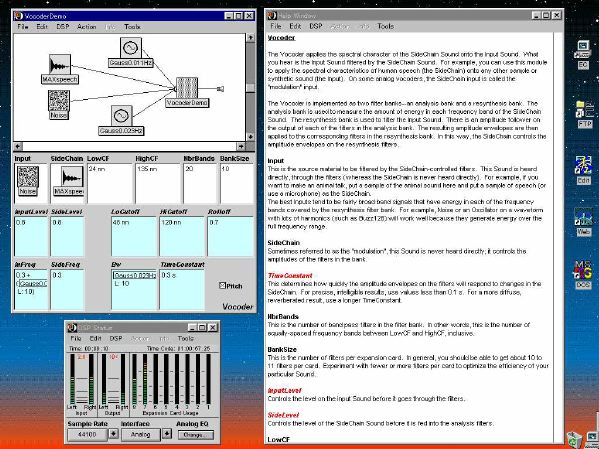
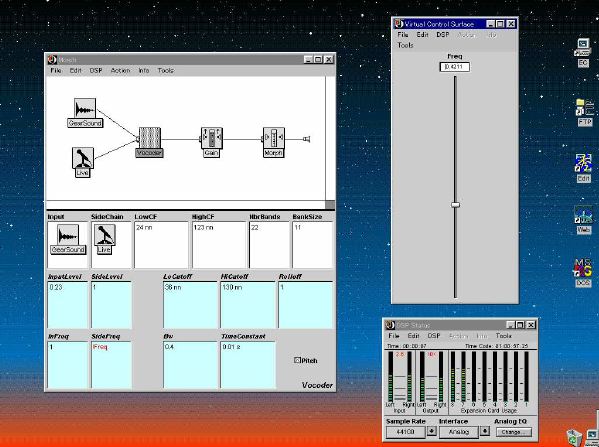
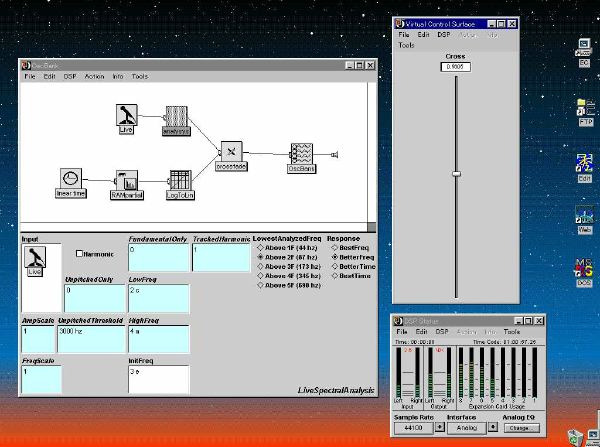
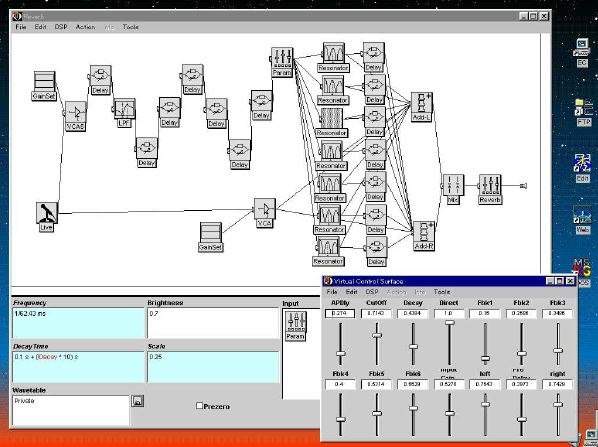
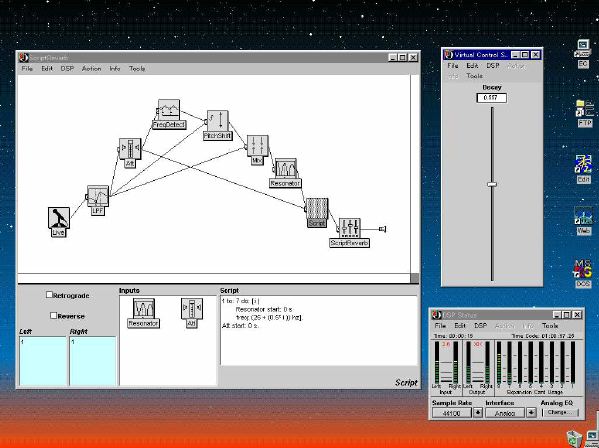
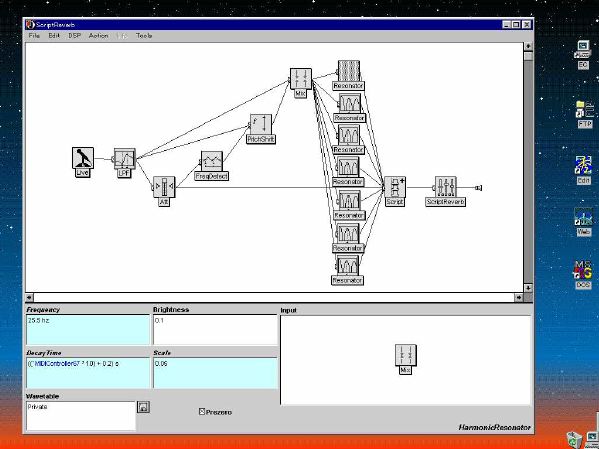
1. 楽音合成の意義本項では「楽音合成」という言葉を、「音響合成」と「音響信号処理」を まとめた広い概念として、音楽に用いられる音素材を生成する部分、と いう意味で用いる。そして、この楽音合成のアルゴリズムに関して、 具体的なサンプルサウンドを豊富に紹介して、体験的に理解 することを目指していく。 なお、「音」に関する重要な研究分野としては、電子的な音響合成システム から出力された電気的信号を空間音響に変換する「音響工学」や、音の知覚 から音楽の認知に至る「音響心理学」などがあるが[1][2]、前者は本書の 対象とせず、また後者は他章で紹介することになっている。 さらに、コンピュータ音楽における「音楽音響学」的なアプローチの 歴史的および技術的な解説、さらに全般的な解説については、参考 文献[3]-[7]なども参照されたい。ここで紹介する楽音合成アルゴリズム 例は、あくまでそのごく一部である。市販の電子楽器はアナログ音源方式の長い歴史を経て、現在ではほとんどが PCM方式となった。たとえば電子ピアノ内部の大容量ROMは、世界的名器 とされるアコースティック・コンサートグランドピアノの音響をデジタル 記録したPCMデータで一杯である。この録音データは、演奏された鍵盤の 音程と打鍵の強弱(タッチ)データに応じて読出され、D/Aコンバータで変換 されて音響出力となる。PCMデータ幅を16ビット、サンプリング周波数を 50KHzとして単音の音響を10秒間ずつ記憶し、それを88鍵(ピアノの音色は 鍵盤ごとに異なる)と50段階のタッチ量ごとに用意すると、全体で 約35ギガビットのデータ量となる。そこで、音域を粗く分割して異なる 読出し速度で共通の波形を読み出したり、タッチ量を単純に音量(振幅)に 作用させて音色ごとのメモリを持たない、等の便宜的な手法で大幅な情報 圧縮/コストダウンを行っている。 このようなPCM録音による音源方式は、ディジタルオーディオと同様に、 再生音響をスピーカから聴く人にとっては本物らしく聞こえる。 電子ピアノでは演奏者の演奏技術に関係なく、猫が鍵盤スイッチを 踏んでも同じ音響を発生する。記録されたデータの呼び出し(再生) では、演奏者の微妙な演奏のニュアンスを反映させられないのは 当然で、より密接に人間の制御と発音機構が結び付くバイオリンや フルート等の音響に至っては、まったく論外である。 パソコンのマルチメディア化が当然のものとなり、CD品質の音響生成が 可能になってきたが、これもあくまで再生専用のものである。ビープ音、 FM音、PCM音と進化してきた音響合成の技術は、警告音や単なるBGM、 あるいは音響データの切り貼りで済む分野、楽器を弾けない人がパソコン で楽しむ音楽(リスナーとしての参加)等では今後も健在であろう。 しかし、より創造的なコンピュータ音楽(作曲・演奏・芸術)の領域 では、音楽のもっとも基本的な構成要素である「音」そのものにも、 あらゆる微妙なニュアンスを実現しうる、なるべく多種のパラメータ を持った楽音合成が求められている。例えば、メーカは「誰にでも簡単に 弾ける楽器」を大量生産するのに対して、専門家は「簡単には演奏技法 を習得できない新楽器」を求めている。これは、センサ部分にも音源部分 にも、なるべく数多くの自由度と可能性を持つことで、音楽芸術の深遠な 世界や音楽演奏の場の緊張感と表現力を持ちたい、という切なる希望 なのである。プリセットの音色波形メモリとか、楽器メーカに固定された 音源専用LSIの枠組みだけでは、楽音合成の可能性としてあまりに限定 されている。そこで、世界中で多くの研究者/音楽家によって、ここで 紹介するような各種のアルゴリズムによる楽音合成方式が検討されて いるのである。 2. Kyma楽音合成を実現するためには、具体的なプラットフォームが必要である。 まだリアルタイム処理が不可能だった時代には、大型計算機で 「非実時間的」に計算された最終結果をRAMに置いて、これをD/A変換して 音響信号とした。次の世代では、ディジタル信号処理プロセッサDSPを 利用して、コンピュータ内のDSPや拡張DSPボードによって信号処理を 実現した。さらに、コンピュータ中枢のCPUの処理能力向上によって、ある 程度のレベルまではソフトウェアだけで実現できる状況になり、アルゴリズム によって自由な「音創り」を手軽に行える環境が整いつつある。本項では、Symbolic Sound社の"Kyma"というシステムを例に、楽音合成 アルゴリズムについて紹介していく。このシステムは "Sound Design Environment"と銘打たれているもので、DSPを多数搭載した Capybaraというハードウェアと、MacintoshおよびWindowsの両方をプラット フォームとしてSmalltalk環境下で同等に走るソフトウェア、の組合せから なるものである。単なる音源マシンというよりも、アルゴリズム作曲から 音響解析、音響データベース、音律、音響信号処理まで、コンピュータ音楽 の広範な研究テーマをサポートするという構想を実現したシステムである。 Kymaについて詳しく紹介する紙面はないので、興味のある読者は 同社のWeb(http://www.SymbolicSound.com)を参照されたい。 ちなみに、筆者はこの項の記事を書く10日前にKymaを初めて入手し、1週間で 概要を把握でき、続けてこの原稿を実質4日間で書き終えた。この事実は、"MAX" と共通の、「余計な専門的技術をブラックボックス化」した、優れた環境の 証明となっているだろう。
ここで、参考までに筆者の環境を紹介しておこう。
これ
は、筆者の自宅の自室の机の上である。
ハンダ付けやマイコン開発などハードウェアの開発も、
ソフトウェアのプログラミングも、インターネットのアクセスも、
電子メイルの読み書きや原稿執筆も、皆ここである。仕事の内容に
よって、機器や機材があちこち移動することはもちろんであるる
Kymaのマスターに挑戦した1週間は、PowerBookの下のWindowsパソコンでの
メイル等のアクセスを低下させることとなった。
図0 は、筆者がKymaを学び始めて数日たった時点での、Kymaの走るパソコン 画面上に並んだいくつかのオリジナル"Sound"のアイコンである。Kymaでは、 MAXならオブジェクトとかパッチと呼ぶ、それ自身がサウンドやMIDIなど の音楽情報/信号情報を扱う一連のソフトウェア部品(ブロック)を "Sound"と呼ぶ。本項に限り、Soundを一般的な「音」でなくこの意味で 使うので注意されたい。 ここに並んでいるSoundには、システムがPrototypesとして提供している サンプルだけでなく、筆者がSoundEditorやClassEditorというKymaの ツールで新たに作ったものも多数、登場している。MAXでお馴染みの、 「既存のソフトウェア部品という資産を再利用する」という オブジェクト指向のメリットは、Kymaにおいても最大限に活用できる。 ここまでがイントロである。以降は、紙面の許す限り、楽音合成 アルゴリズムの例を紹介し、対応したサンプルサウンド (共立出版bit別冊「コンピュータと音楽の世界」付録CDROMの サウンドトラック)をオムニバスに楽しんでいただければ幸いである。 3. 楽音合成/音響信号処理アルゴリズム集●サイン合成(Sample Sound NO.1)楽音合成の基本中の基本といえば、フーリエ分解でお馴染みのサイン合成 アルゴリズムである。 ここでのサンプル音(Sample Sound NO.1)は、Kyma上で 図1 のような構成の"Sound"(本節では「楽音合成アルゴリズムを実現する 一単位のデータ」の意味)で生成した。図中の"Spectrum"では1倍音から 16倍音までの高調波成分の強度を、画面内のスライダーで変化させる ようにしてあり、"OscBank"のオシレータバンクで生成しながらマウスで 個々の倍音強度を変化させて録音した。 定常的な楽音については、128倍音程度までのサイン波のパーシャルに よって、どんな波形でも実現できるが、音として面白くなるのは、 それぞれのパーシャルの強度が別々に時間的に変化するところ からである。●振幅変調(Sample Sound NO.2)440Hzのサイン波に対して、この半分の強度のサイン波で0.5倍から 1.5倍までの深さの振幅変調(AM : amplitude modulation)をかけた、 というのが次の例(Sample Sound NO.2)である。基本要素としては、 図2 のように二つのサイン波しか持っていないというシンプルなものである。 ここでは変調をかける方の周波数を、マウスによって0.5Hzから100Hz付近 まで変化させ、再び戻してみた。 低周波領域では振幅変調の効果が「トレモロ」のように知覚されるが、 変調周波数が高くなると、音色そのものとして影響してくるのが判る。●リング変調(Sample Sound NO.3)440Hzのサイン波に対して、今度は同じ強度のサイン波を、符号を 含めてプラスマイナス1の値の変調波として乗算した「リング変調」 (RM : ring modulation)が次の例(Sample Sound NO.3)である。 基本要素としては、 図3 のように、Kymaの場合にはAMでプラス1を加算する必要もなくなる ので、よりシンプルとなる。 この例では、被変調波440Hzに対して、対等な変調波を数Hzから1000Hz まで変化させたので、両者の「差音」が、途中で両者の周波数が一致する あたりで相殺されることなども判る。●周波数変調(Sample Sound NO.4)二つのサイン波、というもっともシンプルな要素からなる音源の もう一つは、既に古典となった周波数変調(FM : frequency modulation) である。この例(Sample Sound NO.4)では、 図4 のように、周波数1000Hzと振幅1を固定したサイン波の周波数成分と して、数Hz程度から100Hz付近までをおよそ3等分した4個所の周波数 のそれぞれにおいて、変調度をゼロから20まで上げてまた戻す、という サイン波の変調を与えた。●FM音と自己相似系による自動演奏サンプル(Sample Sound NO.5)この例(Sample Sound NO.5)は、Kymaの持つ演奏情報記述スクリプト のサンプル例でもある。アルゴリズムは一見すると 図5 のようにやや複雑であるが、基本的には一つのサイン波ジェネレータに 3つの要素の合計としてFMをかけているだけである。この例では、 5拍子のたった3音からなるフレーズを元にして、自己相似アルゴリズムで 移調したフレーズを重ねた演奏を実現するスクリプトに基き、シタールに 似た音色の8音ポリフォニックFM音源として自動演奏するように設定 してある。FM音の楽器に外部からシーケンサで指令しているのでなく、 楽音合成機構そのものに音楽生成アルゴリズムも組み込むという、 音楽的に重要な発想の転換を実現するものである。●パルス幅変調(Sample Sound NO.6)サイン波の次に基本的な波形としては、量子化方向に1とゼロの2値 しかとらず、時間軸方向に周期に対して可変幅を持つ「方形波」がある。 この例(Sample Sound NO.6)では、基本となる方形波の デューティ比を変調するパルス幅変調(PWM : pulse width modulation) を利用し、ホワイトノイズをサンプリングして得られた乱数で、 方形波の周期、デューティ比、さらに後段のローパスフィルタLPFの カットオフ周波数を刻々と変化させつつ無限ループを回っている。 このSoundのアルゴリズムは 図6 のようなもので、長い周期でパルス列をリトリガするスクリプトによって ホワイトノイズのピーク値をサンプルしてパラメータに利用している。●鋸歯状波の多重生成(Sample Sound NO.7)方形波と並んでアナログシンセの時代を支えたのが、ランプ(Ramp)関数 とも言われる「鋸歯状波」である。 図7 のようなアルゴリズムからなるこのサンプル(Sample Sound NO.7)では、 ステレオ定位の異なる4系列のまったく同じ構成の4音を足し合せて いるだけである。4系列ともローパスフィルタLPFは音色を整える 単なる固定フィルタであるが、ジェネレータは単なる単一の鋸歯状波 生成器でなく、ここでは10個の鋸歯状波から構成される合成音を生成 するモジュールである。パーシャルの波形はサインとは限らないのである。 そして4つの系列の唯一の違いは、それぞれに用いるピッチと位相を、 全て微妙に変えてあるところであり、この単純な差からうねるような独特の 響きの効果を得ている。●ホワイトノイズと櫛型フィルタ(Sample Sound NO.8)アナログシンセサイザーの時代からお馴染みのフィルタは、人間の 聴覚機構とも類似しているために、感覚的に親しみやすい。 このサンプル(Sample Sound NO.8)では、 図8 のような簡単なアルゴリズムによって、ホワイトノイズにもっとも 単純なディジタルフィルタをかけてみた。フィルタはフィードバックを ゼロとして、入力信号に対して可変時間の遅延をかけた信号をそのまま 足し合せているだけである。最初のあたりのステップが荒いのは、 1ポイントの遅延によって櫛型フィルタの減衰ピークがノイズの周波数 帯域の中央にいきなり出現し、そこから整数倍の粗さで移動していく からである。●シェパード・トーン(Sample Sound NO.9)音源というよりも聴覚心理学/音楽心理学の領域で有名な 「シェパード・トーン」である。これは、「無限に上昇し続ける音」 あるいは「無限に下降し続ける音」として人間に知覚されるもので、 サンプル(Sample Sound NO.9)では、 図9 のようなアルゴリズムで実現している。ここでは256個のサイン発生器 バンクに対して、一定の割合で上昇/下降するランプ関数によって それぞれの倍音成分の周波数と強度変化を、ある仕組みで操作する ことによって、この聴覚的錯覚を実現している。タネ明かしはしない ので、初めてこの音を聴いた読者はその原理を考えてみて欲しい。 最初は少ないパーシャルで下降させ、途中でパーシャルを増やして、 今度は上昇させているが、このような動的な制御はDSPのもっとも 得意なところであろう。●フォルマントフィルタ(Sample Sound NO.10)人間の声は、声帯で発生したノイズの多い原音が、咽喉・咽頭蓋・鼻腔など の複雑な共鳴機構によるフィルタによって周波数特性を加工されたものである。 この、いくつかの特徴的なピーク周波数を持つフィルタが「フォルマント」 フィルタであり、このサンプル(Sample Sound NO.10)では、 図10 のように、鋸歯状波オシレータを原音信号として、二つのピークを持った フォルマントフィルタを、ピーク周波数を変えて二つ並列駆動している。 録音では中心となるピッチを4段階にわたって移動させ、それぞれ7種類の 母音に相当するフォルマント周波数をさらに移動させてある。固定的な 母音を選ぶ「音声合成」システムと違って、このなめらかな変化は音楽の 素材となるような可能性を秘めているようにも聞こえる。●タイムストレッチと周波数スケーリング(Sample Sound NO.11)このサンプル(Sample Sound NO.11)では、 あらかじめサンプリングされた共通の元サンプルに対して、 4つの系列ごとに、ノイズをサンプリングして刻々とパラメータを ランダムに変化させ、同じピッチで時間軸だけ伸縮する「タイム ストレッチ」と、同じテンポでピッチだけ上下させる「周波数 スケーリング」をかけた。 この信号処理は内部的にはかなり複雑だが、Kymaでは 図11 のように、専用の処理モジュールによって比較的シンプルとなる。 このサンプルサウンド自体と同じサウンドは、元サンプルを生成した MAXのパッチ側でも実現できないことはないが、このように信号処理側 での加工によって容易になる、という実例となっている。●グラニュラーシンセシス(Sample Sound NO.12)グラニュラーシンセシス(Granular Synthesis)とは、グレイン(Grain) と呼ばれる単純なインパルス波形(急激な変化はノイズとなるので、 一般にガウシアンのような窓関数の形状を持つ)を、時間的・空間的・ 周波数分布的に、ある種のランダム性をもって多数ばらまく、という 手法の楽音合成アルゴリズムである[8]。 ここ(Sample Sound NO.12)では、 図12 のように、3系列のいずれもガウス窓をかけたサイン波をグレインとして、 ランプ関数で時間的にパラメータを変化させている。 一般の楽音合成のように「周期的」なものを持たないユニークな方式で あるが、リアルタイムに実現するには信号処理が重いために、15年間ほど マイナーな方式として埋もれていた。最近のコンピュータの能力向上で 手軽に実現するようになると、その独特の音響がいろいろな作品で 使われるようになった。●グラニュラーサンプリング(Sample Sound NO.13)このサンプル(Sample Sound NO.13)では、サンプル11と共通の あらかじめサンプリングされた元サンプルを使用して、そこから ガウシアン関数をかけて任意に切り出した音響断片をグレインと して用いた。 アルゴリズムとしては、グラニュラーシンセシスを処理モジュールと して持っているKymaでは、 図13 のように非常に簡単である。 この「グラニュラーサンプリング」の印象的なサウンドの登場によって、 グラニュラーシンセシスもエフェクトの概念も新しい時代を迎えることに なったという、画期的な手法である。●ピッチトラッキング(Sample Sound NO.14)ここからは、リアルタイムに入力されるライブ音響に対する信号処理 の例である。 図14 のように極めてシンプルな構成のアルゴリズムによる このサンプル(Sample Sound NO.14)では、左チャンネルには、 リアルタイムにMAXでランダム生成されたスピーチサウンドを、 ライブ入力したそのままで比較のためにスルー出力している。 そして右チャンネルでは、音源として鋸歯状波を使い、これを 共通のライブ入力の「ものまね」として鳴らしている。 まずピッチについては、入力信号に対する「ピッチトラッカー」に よって、リアルタイム周波数分析結果を使用する。 エンベロープ(音量の振幅)についても、「アンプリチュード・ フォロワー」という、一種のサンプルホールドの出力レベルを 反映させている。入力が複雑なスピーチのため、子音などの爆発音 でピッチ抽出に失敗する様子もよく判る例である。●ライブ入力へのAMとRM(Sample Sound NO.15)サンプル2とサンプル3にあった振幅変調AMとリング変調RMを、ライブ 入力の音響に作用させた例である。 このサンプル(Sample Sound NO.15)では、 図15 のように、同じSound内でキャリア信号のサイン波に加算する定数の 値もマウスで可変できるので、いわばAMとRMとの間をモーフィング することもできる。 ここでは全部で20フレーズのランダムスピーチ入力に対して、前半 はAMとしてトレモロ効果の低周波から1000Hzまで次第に上昇させ、 11個目の後半からは定数をゼロとしてRMに切り替え、キャリア周波数 を1000Hzから1Hz以下まで次第に下降させた。●SSBモジュレーション(Sample Sound NO.16)通信分野で使用される変調方式に、SSB(single side band)というものが ある。これは、リング変調によってキャリア信号成分をキャンセルした 上で、キャリアを対称軸として上下に同じ周波数成分が分布すること に注目して、その片側をフィルタで除去してしまい、占有周波数帯域 を半分にする、という手法である。このため、通信機でSSBの無線交信を 受信していると、送信側と周波数がずれた時にピッチのずれた声となる。 このサンプル(Sample Sound NO.16)では、 図16 のように、Kymaの持つ「SSBリングモジュレータ」という専用モジュール でこれを再現した。ここでは位相シフトによってSSBを実現している。●ディレイ(Sample Sound NO.17)ディジタルフィルタでは、サンプリング単位の時間遅延というのが もっとも基本的な要素である。 このサンプル(Sample Sound NO.17)では、まずライブ入力を リアルタイムにサンプリングしてRAMに置きつつ左チャンネルから スルー出力ししている。そしてさらに 図17 のように、直後、0.1秒後、0.2秒後という3系列の遅延によってこの RAMを呼び出してミックスしている。ただし、同時に低周波のランプ関数 によって読み出しピッチも変化させているために、時間的に雰囲気の 変化するサウンドとなっている。●グラニュラーリバーブ(Sample Sound NO.18)このサンプル(Sample Sound NO.18)はサンプル13と似ているが、 重要な違いとして、リアルタイムにライブ入力サウンドをサンプリング して、そこにガウシアン関数をかけてグレイン化しグラニュラー シンセシスを行っている、という点に注目して欲しい。 これは通常はなかなか実現が困難であるが、Kymaではグラニュラー シンセシスの処理モジュールの入力として「DSP内のRAMにあらかじめ 置いた波形を読み出し」「サンプリングしているRAMから直接読み出し」 を選択できるので、 図18 のようにシンプルに構成できる。●ピッチシフト(Sample Sound NO.19)このサンプル音(Sample Sound NO.19)はサンプル11と似ているが、 ライブ入力をサンプリングしていない(当然、その読み出しも していない)点に注目して欲しい。 ここでは 図19 のように、まずライブ入力をリアルタイム周波数分析して、 周波数軸上でスケーリングし、これを元にしてサイン発生器バンクに よって、100倍音までのサイン合成によって音声合成している。 個々の倍音成分の強度をリアルタイムに制御して、ピッチや フォルマントを自在に変化させながら、入力音声と同じ「言葉」を 再現しているのである。●トラッキングフィルタ(Sample Sound NO.20)このサンプル(Sample Sound NO.20)はサンプル14に似た例で、 リアルタイム入力に対するピッチトラッキング情報とピーク検出 情報からローパスフィルタLPFのカットオフ周波数と周波数スケーリング を動的に変化させ、このLPFの入力としてはピッチトラッカーの出力 によって鋸歯状波を与えている、という簡易型の音声合成になっている。 システムは 図20 のようにシンプルだが、無音状態からの立ち上がりの瞬間は追従しきれず に直流成分ノイズが乗っている。これをキャンセルするためにはどうすれば いいか、というのは課題として残しておくことにしよう。●ロボタイズ1(Sample Sound NO.21)リアルタイムの周波数分析処理をうまく利用した面白い例として、 このサンプル(Sample Sound NO.21)では、ライブ入力から ピッチの変動を意図的に除去する、という操作を行っている。 図21 の構成ではよく判らないが、実際に楽音を再合成するための サイン波オシレータバンクの各パーシャルを与える"FreqScale"の モジュールでは、周波数解析の結果パラメータを逆数として 与えているために、元々のピッチ変動がキャンセルされて、無機的な ロボット音声が生成されるようになっている。 またこの例では、処理によるサウンドの遅れが、左チャンネルの原音 に対する右チャンネルの遅れとして実感できる。平板な合成音とは いえ、周波数解析とスケーリングを行い、これを受けて80個の オシレータバンクで再合成すれば、このくらいの遅延が生じるのである。●ロボタイズ2(Sample Sound NO.22)この例(Sample Sound NO.22)では、50のパーシャルからなる サイン波オシレータバンクで再合成するための周波数パラメータ の経路に並列に櫛型フィルタを置き、ここにノイズを2重にサンプル ホールドして、やはり周波数の逆数として与える、という 図22 のような面白い構成となっている。 昔のSF映画に出てくるロボットのようなサウンドで、しかもリアルタイム に入力される音声と同じフレーズを生成するためには、このような DSPの処理が必要になる、という例である。サンプル21に続いてこの例でも 遅延があるが、これはリアルタイム周波数解析モジュールの設定として 「反応速度優先」でなく「周波数精度優先」の方を選んでいるためである。●ボコーダ1(Sample Sound NO.23)アナログ時代のボコーダとは、多数に分割したバンドパスフィルタ群の ゲインを入力信号の周波数成分のレベルに対応させる、というエフェクタ だったが、DSPによってディジタル化されて意味合いが拡大された。 この例(Sample Sound NO.23)では、同じライブ入力を 図23 のように3個所で使用している。左チャンネルからスルーしているのは 比較のためであり、残りの二つが、ボコーダをかける分析側だけで なく、ボコーダをかけられる側のオシレータの周波数トラッキングにも 使われている。結果として、パラメータをマウスで(もちろんMIDIに 割り当てるのも容易)変化可能な、不思議な「声」を生成している。●ボコーダ2(Sample Sound NO.24)こちらはアナログ時代からお馴染みのボコーダサウンドかも しれない。サウンドとしての入力にはホワイトノイズを用いて、 分析側の入力に、これまで何度となく登場しているものと同じ MAXによるランダムスピーチ音を使用しているが、 この例(Sample Sound NO.24)では、もはや元の音声としての 情報は失われている。 全体を特徴づけているのは、 図24 のように、周波数とバンド幅のパラメータに二つの超低周波数の ガウス関数オシレータを用いているためで、両者のずれのために、 全体の音響の周期は非常に長いものとなっている。●モーフィング1(Sample Sound NO.25)同じボコーダの応用として、この例(Sample Sound NO.25)では、 ギヤの回るようなノイズ音とMAXからのスピーチサウンドとの間で、 マウス操作のスライダーでなめらかに変化させる、一種の モーフィングを実現している。 システム構成は例によって、 図25 のように極めてシンプルである。Kymaでは1倍以上のゲインを MIDI等の「ホットパラメータ」では設定できないので、このように 定数倍の増幅器と動的な減衰器を組み合わせてライブ制御を 行っている。●モーフィング2(Sample Sound NO.26)モーフィングの例として、今度(Sample Sound NO.26)は、 4秒間でループしている鐘の音と、同じMAXからのスピーチ サウンドとの間で、マウス操作のスライダーでなめらかに連続 変化させてみた。 こちらのシステムは、 図26 のように、音源部分が100個のサイン波オシレータバンクであるために、 モーフィングのためのクロスフェード用モジュールには両方の入力 の周波数解析結果を与えることとなる。この例では鐘の音については あらかじめサンプリングした音を固定ファイルとして使用しているが、 両方ともライブ入力して、そこで漫才でもやったらどうなるか、 興味のあるところである。●リバーブ1(Sample Sound NO.27)最後の例はリバーブである。ここ(Sample Sound NO.27)では、 図27 のように非常に複雑なシステムのように見えるが、実は7系列のディレイ とレゾナンスフィルタを並べて、プリディレイとしても6段の ディレイを置いているだけのものである。 このようなSoundは、雛形として1つだけ作ってしまえば、Smalltalkの オブジェクト指向環境によって、同じ特性を継承したブロックごと 簡単に複製して増設していけるので、思ったほど面倒ではない。 そしてほとんど全てのパラメータを、画面のスライダーや MIDIによって自在に変更することができる。●リバーブ2(Sample Sound NO.28)サンプルの最後は、もう一つのリバーブである。この例(Sample Sound NO.28) では、システムが 図28 のように、かなりすっきりとしている。可変パラメータも一つだけと シンプルである。しかし実は、"Script"というモジュール内に記述 されたたった4行のスクリプトがこれを実現しているのである。 この画面の状態で「展開」を指示すると、なんと 図29 のように展開されて、この差に圧倒されてしまう。スクリプトの効用 そのものである。コンピュータ音楽の研究が続く限り、楽音合成/音響信号処理の 探求は続けられる。新しい音のアイデアは新しいシステム/楽器の 登場をもたらし、そして新しい音楽の原動力となる。 人間の聴覚という神秘とともに、音の探求は夢にあふれた世界なのである。 参考文献[1]Bowles, Edmund A.:Musicke's Handmaiden あるいは芸術に奉仕する テクノロジーについて, コンピューターと音楽, pp.11-29, カワイ楽譜(1972). [2]Pierre Schaeffer:音楽・言語・情報理論, エピステーメー, pp.87-101, 朝日出版社(1976). [3]中村勳:音楽・楽音・コンピュータ, コンピュータと音楽(bit別冊), pp.54-64, 共立出版(1987). [4]中村勳:計算機の音楽音響学への応用, 情報処理, Vol.29, No.6, pp.549-556, 情報処理学会(1988). [5]Julius Orion Smith:Viewpoints on the History of Digital Synthesis, Proceedings of 1991 ICMC, pp.1-10, Montreal(1991). [6]長嶋洋一:楽音合成技術, 音楽情報処理の技術的基盤, pp.12-23, 平成4年度 文部省科学研究費総合研究(B)「音楽情報科学に関する総合的研究」調査報告書(1993). [7]長嶋洋一:音素材の生成, 情報処理, Vol.35, No.9, pp.808-814, 情報処理学会(1994). [8]長嶋洋一:Granular Synthesisの音響パラメータの検討とその制御, 日本音楽知覚認知学会秋季研究発表会資料/日本音響学会音楽音響研究会 資料 Vol.14, No.5 (ISSN 0912-7283) , pp.37-44, 日本音楽知覚認知学会/日本音響学会(1995). |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}