音学シンポジウム発表参加 (第39期・虎の穴)
2013年5月 長嶋洋一
2013年5月11-12日、お茶の水女子大で開催された、情報処理学会 音楽情報科学研究会 第99回研究会「音学シンポジウム」に発表参加しました。 今回はSUACのスタジオレポートをパネルセッションで発表し、実際には院生のリュ君と3回生の森川さんがそれぞれiPadを手にプレゼンしました。今回の同行者は、「ジャミーズ娘+」で活躍した3回生の森川さんと、交換留学生からSUAC大学院に来てくれたM1のリュ君の二人です。



会場のお茶の水女子大は厳戒警備でした。 まずは午前の招待講演セッションです。







★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★
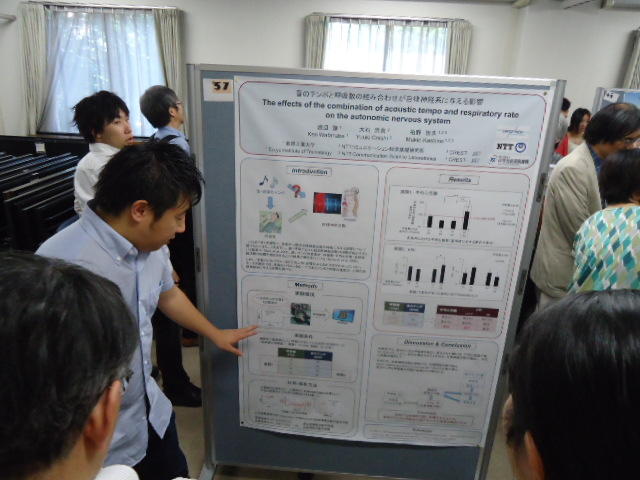
初日のポスターセッションです。 このシンポジウムでは12人の招待講演をシングルトラックで全員が聞くために、一般発表は全てポスターとしました。




































7階の会場に戻って、午後の招待講演セッションです。






★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★
晩には懇親会がありました。 ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★
2日目となりました。 会場設営の手伝いがあったので、学生とちょっと早めにホテルを出て会場へ。 朝イチのセッションは、我らが片寄さんと後藤さんです。





★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★
講演後の、音楽情報処理研究界のスーパースター・後藤さんと話す森川さん。 これはお宝画像です(^_^)。

★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★
この日の昼休みは、音楽情報科学研究会の運営委員会がありました。




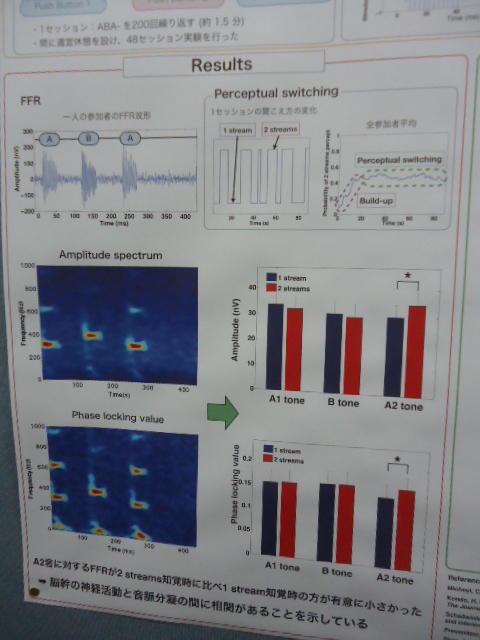
そして2日目のポスターセッションでは、SUACの発表を、2人の学生がプレゼンターとして頑張りました。
































































午後の最後の招待講演セッションです



★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★ ★
クロージングです。また来年あるのでしょうか。






森川 真衣
いろんな分野から音を学ぶという今回の学会でしたが、とても勉強になりました。 正直に言うと、提示された数式は(私の勉強不足もあって)そんなに理解出来ません でしたが、先生がおっしゃってた様に、自身の創作のタネになる様なものばかりで、 とても充実した2日間でした。 また、実際にポスターセッションの場で研究者(発表者)の方とお話し出来た事が その研究を知るのにとても大きかったと思います。そして、自身が発表者として 立ったときに人に伝える事の難しさを改めて痛感しました。それと同時に伝えたい 事が伝わり、深くお話できたときとても嬉しく感じました。 大学という場で学ぶのは残り少ないですが、日々勉強、精進しようと思いました。 ありがとうございました。リュ・ジュンヒー
今回初めて東京のお茶の水女子大学から開けた音楽情報学研究会に参加しました。 今年の研究会は土日二日間 続けていて午前3時間と午後の3時間は大学の 先生や企業の研究者の最近の研究の動向や新しい技術 などの発表を聞くことが 出来たので新しい作品を作ることについてたくさんのアイディアをもらえる機会に なってましたし、午後に1時間半ずつ進行し、自分も参加したポスターセッションでは 色んな 研究者や先生に自分の作品を含めSUACの様々の作品のことについて発表 しつつ、質問や意見をもらい自分の作品の長所と短所について分かるいい機会ですた。 二日のスケジュールは大変だった けど自分の経験や知識が広がるいい経験でした。 このような機会に参加できるようにたくさんのことを手伝ってくれた長嶋先生に 大変お世話になりましたので感謝申し上げます。■2013-MUS-99 招待講演memo (長嶋)■ (1) 音声認識の方法論に関する考察-歴史的変遷と今後の展望- 河原 達也 ・音声認識は最近よくなった - Siri、放送の字幕、国会の議事録 ・音声認識はメディアアートの対象として面白いか? ・大規模コーパス ・DNN - Deep Neural Network (2) 統計的機械学習問題としての音声合成 徳田 恵一 ・波形の接続による音声合成(コーパスベース) ・ボーカロイドは単一音素(単一インベントリ・ダイフォン音声合成)によるコーパスベース (「あ」は1個しかない) ・過去「音声認識は技術、音声合成は芸術」 ・HMM音声合成→統計的パラメトリック音声合成 →「音声認識は技術、音声合成も技術」としていきたい ・図式としては分析合成方式の音響合成とあまり変わらない ・HMMとかNNとかにあまりソソラレない自分がいる(^_^;) ・補間、外挿(補外)のパラメータをライブ制御できるか? → できる(^_^) ・1次元(2要素)の補間だけでなく2次元の空間で補間・外挿できるか? → できる(^_^) パラメータ(軸)の選び方が重要となる (3) 聴覚における寸法知覚と最適末梢系 入野 俊夫 ・聴覚の基礎(生理学的) ・蝸牛-基底振動膜振動 ・信号処理的最適性→最小不確定性 ・○音聲 ×音声、音声には耳があるのだ ! ・音声 = 音響管 + 音源 → これはインスタになるのでは?? ・聴覚では声道長を認識して大人か子供かを区別している ・音源の寸法知覚(大人の声←→子供の声) 5%、母音だけだと悪化、30ms持続すればOK ・音のラウドネス 10%、ピッチ 1%、光の明るさ 15% ・Mellin変換 - Wavelet(スケール変形)を正規化する手法 ★調べる事 メリンオペレータ(時間×周波数) - 無次元 ・最適解 - ガンマチャープ gammacharp (4) 聴覚情景分析と選択的聴取の脳内メカニズム 柏野 牧夫 ・聴覚情景分析 ・カクテルパーティ ・出現は消失より顕著 (脳内では注意しないと見失う) ・Auditory Scene Analysis ・音脈(stream) ・実環境で起こりがちな現象を事前知識として利用している(無意識にと) ・特徴の隔たりを利用した音脈分疑 ・時間的相関を利用した音脈分疑 ・共変する音響特徴は一つの音脈に群化 ・反復共起に基づく音脈分疑 ・未学習のノイズであっても反復登場すると注意しなくても音響として群化・認識される (DJなどの応用に効く) ・階層的スパース表現の獲得 同時的群化→反復共起 ・聴覚系は階層性・並列性だけでなく双方向性がある ・音脈「知覚」はどこで成立するのか - 分かっていない ・fMRIなど脳内活動にあまりソソラレない自分がいる(^_^;) ・0.5Hzあたりのモジュレーションを引き込むメカニズムが重要では? (30)非同期録音機器を用いたマイクロフォンアレイ信号処理 小野 順貴 ・マイクロフォンアレイの音源分離 - まぁ当然 ・非同期録音機器を利用したアレイ信号処理 ・マルチマイク音源分離にあまりソソラレない自分がいる(^_^;) (31)三次元音場再現方式の概要 安藤 彰男 ・多スピーカで何が出来るか - ネタの宝庫? ・3次元音響(臨場感)の分類 チャネルベースシステム オブジェクトベースシステム シーンベースシスム ・原理による分類 心理音響モデル 物理音響モデル ・2chステレオにおける音像定位 中低域 - 両耳における位相差 広域 - 両耳における強度差 ・中低域はレベル差は小さいので1スピーカでOK ・高域は左右の位相差は分からないのでレベル差で検出 ・サイン則(頭の向きは固定)とタンゼント則(音源の方を向く) ・ミキサーはサイン則 ・あとはノウハウでいい音を作る ・Wave Field Synthesis (WFS) シーンベースからオブジェクトベースに行ける ・球面調和関数によるモデル Max6でシミュレーションできるカモ・・・・ ・音圧をあらわす式には進行波と後退波が現れる ・パラメトリックスピーカアレイの直進スピーカについては? → NHKからは何も出てこない(^_^;) ・NHKではチャンネルごとに別ソースというのは送らない (32)音楽の生成と理解 片寄 晴弘 ・イリアック組曲からCrestMuseまで ・生成理解系の研究はおいしい ・スクリーン写真撮りに没頭 (33)未来を切り拓く音楽情報処理 後藤 真孝 ・後藤パワー炸裂(^_^) ・コンピュータが自動作曲した音楽をコンピュータが自動鑑賞評価する時代? ・使い捨て音楽(握手券の付録CD)の自動作曲は可能か ・パクり疑惑の許容レベルは変化するか ・スクリーン写真撮りに没頭 (34)音声生成過程と信号観測過程のモデルに基づくマルチチャンネル音声強調 中谷 智広 ・音声強調、音声認識 ・音響的状況分析の手法を環境音響の除去に使用する ・生成モデルがあることで予測・推定・認識できる ・認識のための生成モデルにあまりソソラレない自分がいる(^_^;) (35)音声信号における特徴量分離と情報分離 峯松 信明 ・音声信号の特徴量分離と情報分離 ・当該情報に直接関係する不変量を抽出 ・「人間らしい」というのはどういう事か? ・幼児の言語獲得における汎化能力から考える ・汎化能力の発達が遅れる先天的障害者から考える ・動物は絶対音感、自閉症者も多くは絶対音感、移調すると別の曲と認識 ・人間の音声模倣は音響的にズレた模倣、ただし動物は音響的模倣 ・音環境の分布的特性に敏感 - 乳児が示す ・方言性の違いに敏感、話者の違いに鈍感 ・自閉症者は方言を獲得しない ・音楽における方言性 - スケール ・音高の相対音感でなく音色の相対音感を考える ・深層構造としての不変量・共通項 ・音色の動きの中に共通項があるだろう・・・という視点 ・音高は1次元だが音色は多次元なので距離の考え方が変わる ・身体の大きさ、性別、年齢などを捨象して言葉の中身を抽出したい ・世界諸英語 World Englishes ・発音は顔のようなもの、それは個人の個性 ・15億人の英語の距離相関を分析できないか ・人間らしさ - 「計算できる馬」の話題 - 本当に理解しているのか否か (62)音楽・音声処理と統計的自然言語処理 持橋 大地 ・統計的自然言語処理 ・言語は離散、音楽は連続・・・ではない ・歌詞とメロディの話、歌詞生成 ・言語モデルはNグラムだけはない ・前後関係だけでは音楽にはならないのでは? ・言語とメロディー(フレーズ)は同じようには料理できない ・結局、自然言語処理にそれほどソソラレない自分がいる(^_^;) ・意味空間にランダムなオブジェクトを配置するのが作曲? ・統計的機械翻訳 ・確率統計音楽のフレームワークに組み込めるのか?? ・離散の言語処理に連続値の統計的関数を使う (63)聴覚コンピューティングと産業応用 柏野 邦夫 ・聴覚コンピューティング ・CA Computer Audition - CVの対照概念 ・メディア認識 - 媒体から情報(様子)を得る ・共立出版 - コンピュータビジョンの技術 ・CV応用の事例 http://www.cs.ubc.ca/~lowe/vision.html ・そのCA版はどうなるか? ・情報コンピューティングの難しさ ・音響指紋 - 粗く量子化した局所特徴同士の比較 ・状況の監視→アラート